
What happens when you don’t have version control? Industrial automation projects have a ton of moving parts including multiple programmers, tasks, and countless iterations as code is developed and deployed. It can be difficult to track changes and ensure that everything works well together. This is where Git comes in.
When it comes to version control, you can take the classic Ph.D. dissertation approach, with 20+ different file names and multiple “final” versions...
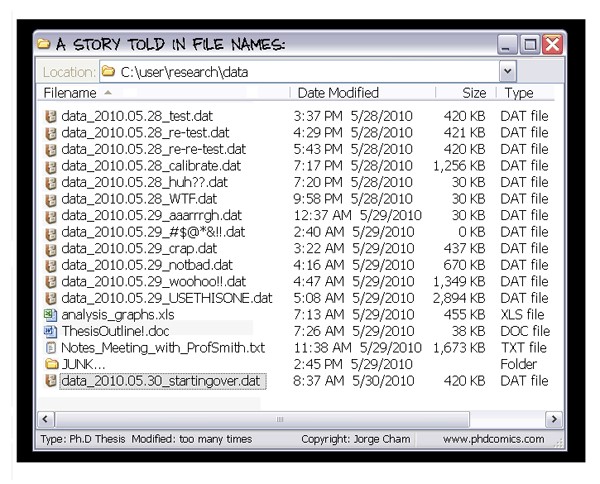
…OR you can try Git, the key to version control and collaborative coding.
Enter Git
Git isn’t exactly the new kid on the block. Pretty much every major player in the software world uses it (or some permutation of it). Google, Meta, Twitter, Microsoft, Amazon, and Netflix all use Git-- and reap the benefits.
You’d think that with all these major companies having Git in their toolkit, everybody would be using it. However, the industrial automation world can sometimes be a bit behind. That’s why it’s important to get the word out on the benefits of Git.

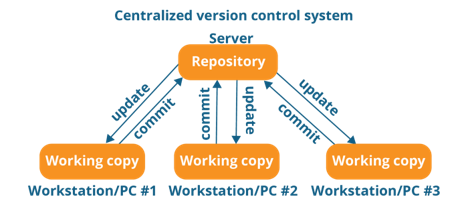
In the world of version control, there are two approaches: centralized systems and distributed systems.Git is an open source, distributed, platform-independent version control system. It was originally created by Linus Torvalds for the development of the Linux kernel.
A centralized system has a single version control server where the code repository (repo) resides. Each user of the codebase maintains a working copy that they publish updates against.
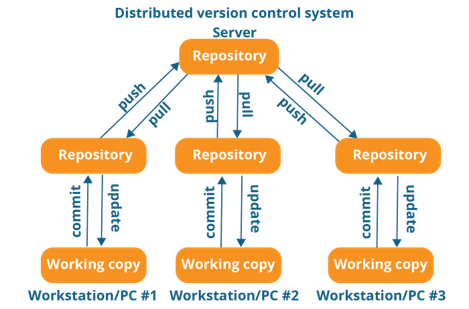
With a distributed system (Git), everyone who is working locally actually has a full copy of the entire repo. Not just the current code base, but every branch, every command, every piece of history in that repo is accessible.
This structure gives users a ton of flexibility with setting up processes and procedures to manage code interactions. The result is better team efficiency.
How Does it Work?
With Git, a history resides in your local system that tracks everything that has happened with your code. Any active branch, every version, every changelog, all of this can be accessed locally through Git.
Currently, we have many Azure DevOps Repositories where we are maintaining internal codebases as well as project-specific codebases so that we are easily able to adapt to changing conditions and compare iterations over time.
What are the Features?
Git as a concept involves a variety of ideas that, when utilized properly, will make your life easier. Let’s explore these ideas and discuss how they come together.
Commit
The core building block of Git is a commit, which is a single point in the Git history. A commit creates a save point within your repository, creating a full instance of the entire code base. This commit is assigned a unique identifier, and the system tracks the user, comments, and timestamp of the submission to build out the entire history.
The word "commit" is often used by Git in the same places other revision control systems use the words "revision" or "version”. The live commit (or version) of the codebase will then only have one instance of every file/resource as opposed to the image below.
Every programmer’s worst enemy is their past self who was not as experienced or who did not like documentation. This framework gives the ability to roll back the live codebase to any commit that has been stored in the system, easily compare a past version of the codebase to the live version, and have greater visibility into what changes were made at each step of the process.
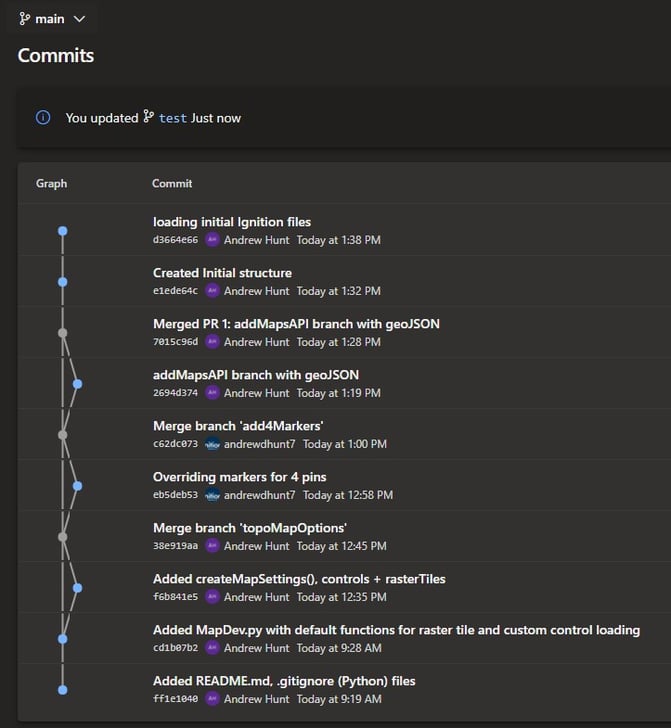 A sample string of commits, each representing a full copy of the codebase.
A sample string of commits, each representing a full copy of the codebase.
Diff
Another feature that many UI’s have within Git is the diff. A diff simply shows the individual file differences between different commits. This is useful for any merge conflicts or if you’re identifying what changes someone made, especially useful when troubleshooting.
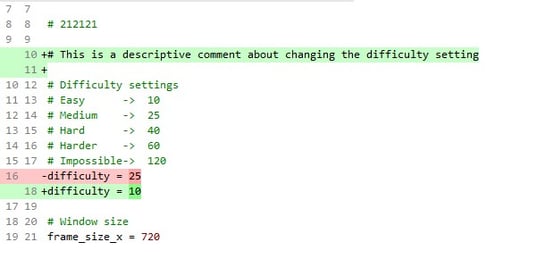
A diff works on a line-by-line basis. So in the example below, the tool shows what lines are being removed, added, or altered in a Python file. Diff tools come with features to individually or bulk-select which version of the code should be maintained in the working copy.
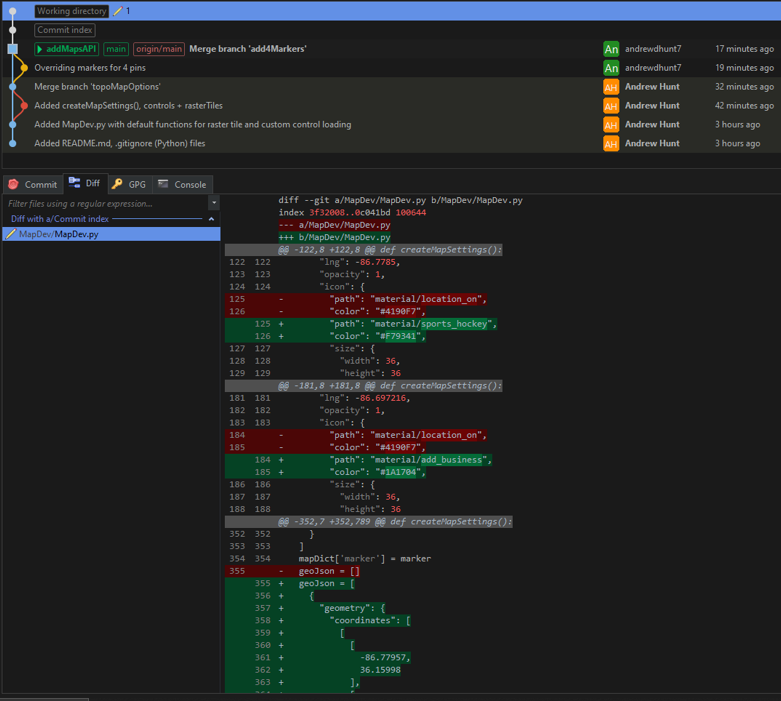
Branching
What happens if I want to test out a new experimental feature that will be disruptive to the rest of the application and may not pan out? Should I create redundant resources? No.
Should I just hope that my new features don’t introduce regressions that will disrupt my team? Of course not.
The concept of branching now comes into play. A branch in Git diverges (or branches out) from the master version of the repo so you can make isolated changes to your code.
When you work on your code in a new branch, it acts independently of the main codebase. You can have another full copy of the same codebase that is isolated on a separate commit. Branching is particularly useful for testing or when you have to fix a bug or add a feature to a portion of code.
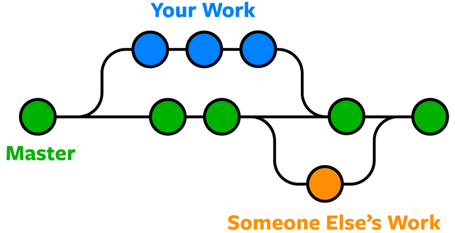
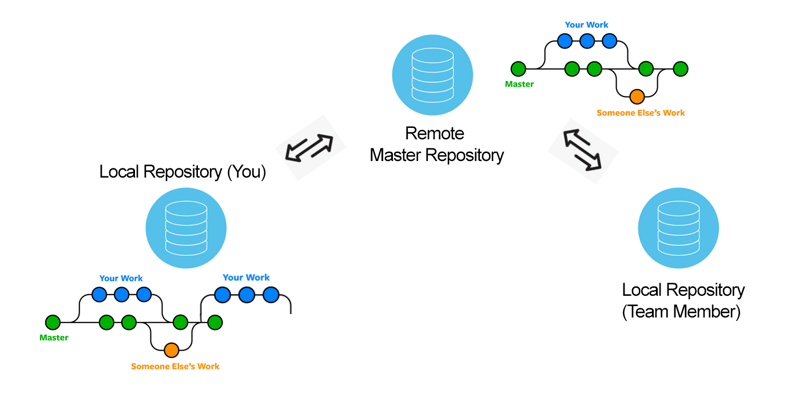
Branching can be useful in the context of a single repo for a single user wanting to test out new features. However, it also gains significant power when combined with the remote repo architecture. When all the local repos are being pushed up on a regular basis, a user can see all of the different branches that currently exist and are being worked against.
With this structure, the remote repo contains your test branch and any other test branches from multiple users. Just make sure you are deliberate with what you’re pushing and when.
For reference, these are the key terms for interactions with the remote repo:
- Fetch – Retrieve information from the remote repo without merging into the local
- Push – sending from the local repo up to the remote
- Pull – Retrieve information from the remote repo and merge into the local
- Rebase – move or combine a series of commits to a new base commit
Using commits, diffs, and branching improves collaboration and ease of development. Everyone can have the same core codebase and work on their own features on their local repo. Then once they’re satisfied, they can bring it all back into the main codebase.
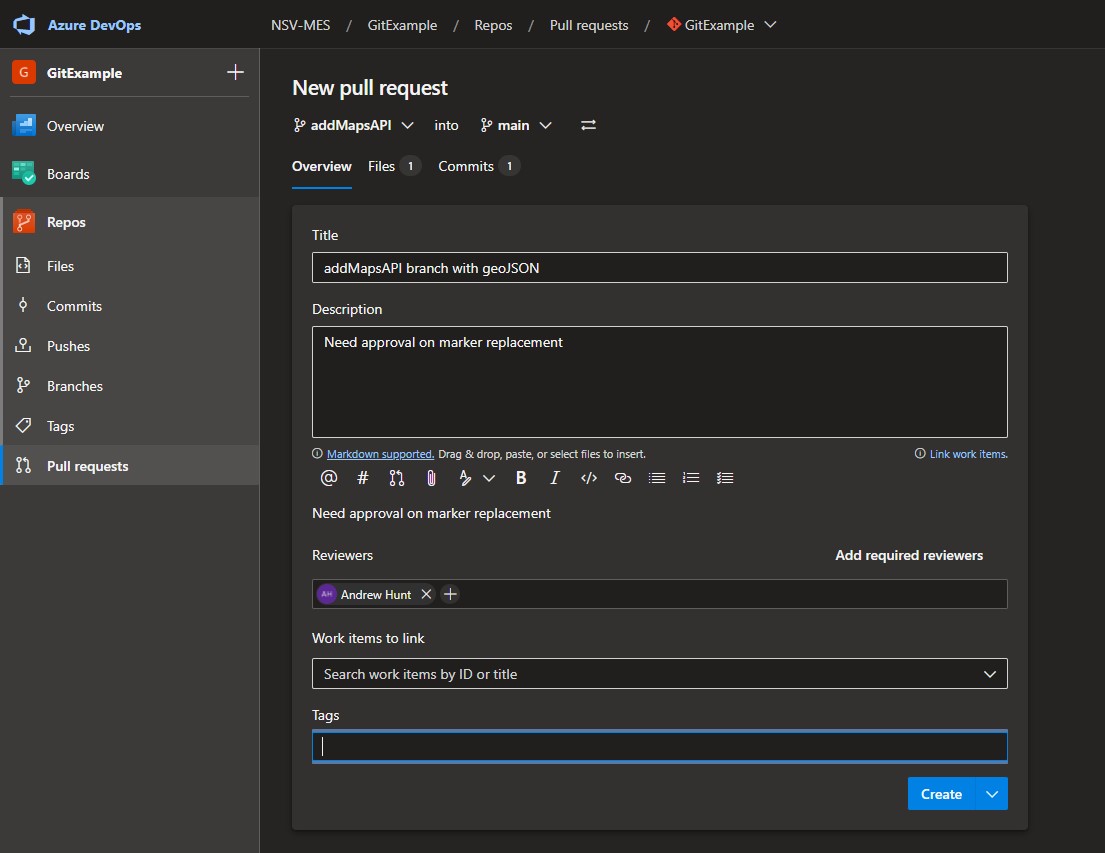
Pull Requests / Remerging Code
When you’re feeling confident with your code, you can create a pull request to bring one branch back into another. For instance, a pull request could be used to take all your test code and pull it back into the main branch. Usually, a pull request requires a review or signoff by another team member. Keep in mind that every commit is a full codebase and that pushes and pulls are simply moving variants of the codebase. You can always run a fetch request to retrieve information from the remote repo without merging into the local repo.
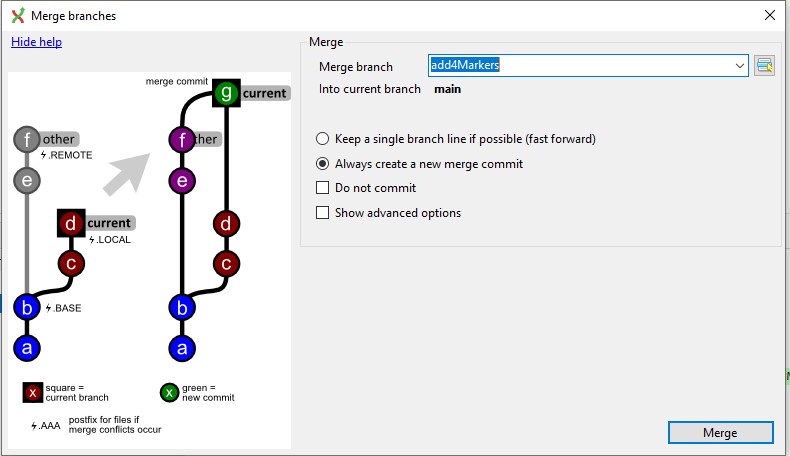
Merge
A merge is bringing two branches together. It’s the official stamp of approval when you expect there to be no conflicts with your code.
Merging a single resource is pretty straightforward. All you need to do is grab the code from your branch, move it into the main branch, delete the separate branch, and bam! Now you only have one codebase line.
But what if multiple people are doing this at the same time? Two people may take their own versions of code, make changes to it, and push it up to the repo. This can result in a merging conflict.
A merging conflict is when two commits try to override the same resource such as a certain line on a certain file. Auto-mering cannot figure out what to do in this scenario, so you will need to manually choose which one of those commits to keep.
As mentioned earlier, Diff tools are extremely beneficial for conflicts that cannot be resolved in an automated fashion. By pulling down a copy of the latest code base, the developer can address any conflicts before merging the development branch.
Key Production Benefits and CI/CD
What’s so important about using all these features? We want to save time and effort so that our teams can go on to bigger and better things and be more confident in delivering systems that are more capable.
Faster Troubleshooting and Recovery
We’ve all been there. You get an urgent call at 3 AM from a customer saying, “Everything’s broken. We need you ASAP!”
There are now two ways to approach this scenario. The first is the hard way where you manually dig through all your program files and figure out which one is causing the problem. It can be a nightmare.
The second is the easy git-it-done way. With version control, you can simply make a backup, roll back to a previous working version, and run a diff on those two commits. Then you can save your progress and sort everything out the next day. All with no sleep lost!
Transparency of changes
If you see some feature that’s behaving abnormally, you can identify who made the change and when they made it. Having the ability to branch and manipulate the codebase also allows for greater interactions with stakeholders and streamlined collaboration among development teams.
Enhanced Collaboration
Let’s say a team of 5 is working on a large-scale MES project. One is working on database design, two on UI, and two on factory connectivity / SCADA aspects. There will inevitably be features that are difficult to develop when all working within a single environment. A change in the database could break the UI. With the proper Git infrastructure, the time spent planning for and solving these issues could instead be used for more development.
Accurate Dev environments
Exact copies of your production environment are available to you. Working with the latest and greatest version for testing and development increases the likelihood that nothing goes wrong with new deployments. Confidence in deployments is crucial in maintaining a roadmap to avoid obsolescence.
Git Into Industrial Automation
We’ve discussed how Git works. We’ve looked at commits, diffs, branches, pull requests, and merging. This all sounds great, let’s look at a few ways this applies specifically to industrial automation.
Works with PLC Code
With PLC code, nearly all vendors can export to some form of a standardized text file which is what you put into version control. When you implement it, it is no different than any other code file. Git doesn’t know or care if the file is a plain text file, JavaScript, or an Allen Bradley RSLogix Export file; it will function the same in each situation.
Ignition Resources
Ignition is a cutting-edge SCADA and MES platform and is being widely adopted across the industry. More and more Ignition data is being fed into the file system with recent versions of Ignition, so there is a greater capacity to control things such as Jython script libraries, Perspective resources, Tag JSON documents, and many more within the version control environment.
Project Execution
If you want to use Azure DevOps as your remote repo host, you’ll find that it makes integrating tasks on the DevOps Boards much easier. When you implement a system like DevOps, you can set links to commits or branches within a repo in Git. Essentially, incremental releases are tied to your project tasks and timeline so it’s easier to track your progress. This helps limit overhead activities and increase visibility with stakeholders.
If you want more info on project management, you can also check out our blog on Agile vs. Waterfall development.
A Few Final Thoughts
There are a lot of misconceptions about how Git works. Let’s break it down to show you what Git is really all about:
1. First and foremost, Git is a version control technology.
Git is the term that refers to the distributed version control technology we have been discussing. This technology has many permutations and forms, but the core functionality is universal.
GitHub, Azure DevOps Repos, BitBucket, GitLab, AWS CodeCommit, and many others are all services that allow for remote cloud hosting of Git Repos among other features and integrations.
Git Extensions, Git CLI, GitHub Desktop, GitKraken, SourceTree, Sublime Merge, and many others are all UI software applications that help with the visualization of and/or interactions with the tool.
Each implementation has its pros and cons, so use what’s best for you and your team.
On that note:
2. Implement what works best for you and your work.
When deciding which services and software to use, one rule reigns supreme: Do what works for you. Teams are different, industries are different, and projects have varied circumstances. While industry standards and best practices are helpful, you want to make sure you are getting tangible benefits compared to your baseline method.
3. Even if you are working alone, a remote repository pays off.
Sometimes your team is just you. Still, please don’t skip version control. Nobody can frustrate you more than past you.
One of the many benefits of Git is you can isolate your tasks in branches and have access to your full history (with comments) which saves you a lot of hassle when you revisit old projects.
4. More use of Git means less work and less stress.
The intent with Git is that once in place, Git will save you time and prevent stress. Instead of going into Ignition designers or digging through PLC backups, Git gives you access to what you need in a matter of seconds. Future you will sing your praises.
It’s simple really…
At the end of the day, Git saves files and Git tracks changes within those files. It’s nothing more complicated than that.
Implementing Git Into Your Projects
Setting up Git and ensuring you have all the right automated tools and supporting procedures in place can be challenging at first. Once Git is up and running, tasks that took hours will now take seconds, but it’s important to get it going correctly. If you need help integrating Git with your workflow, feel free to reach out to our top-notch industrial automation team.





Comments