
In Part 1 of our Git Series, we talked about the purpose of Git (version control) and how it allows for greater collaboration and efficiency in development and deployment. This week, we’re going to look at a few use cases to give you a few examples of what Git looks like in action.
Multiple Source, Independent Git Development
In this first example, we will track two developers’ changes to a piece of code and their interactions with their shared remote code repository.
Ignition Perspective is being used to render the results of the code for easy visualization, but it is important to note that the content of our Git managed codebase in this example is only a single Python code file (.py). This constraint is in place so that we can demonstrate the concepts we talked through independent of some of the challenges that our common Industrial Automation software packages suffer from in current state.
The remote repository is hosted on Azure DevOps Repos, the work of developer “Tony Stark” is shown using the Dark Mode Git Extensions UI, and the work of developer “Reed Richards” is shown using the standard light theme Git Extensions UI. The sequence is:
- Repo is started.
- Tony makes changes.
- Reed makes changes.
- Tony makes additions.
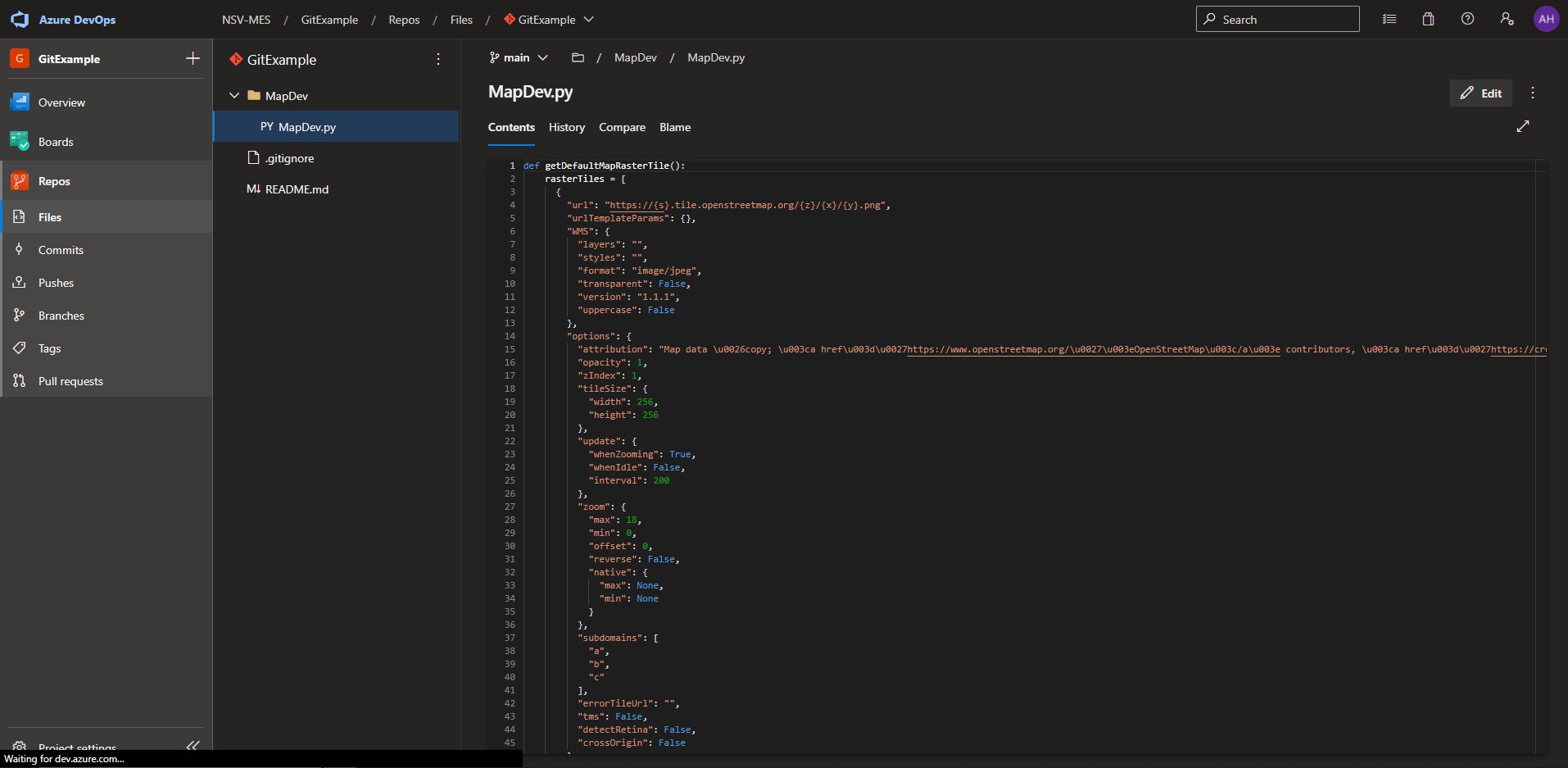
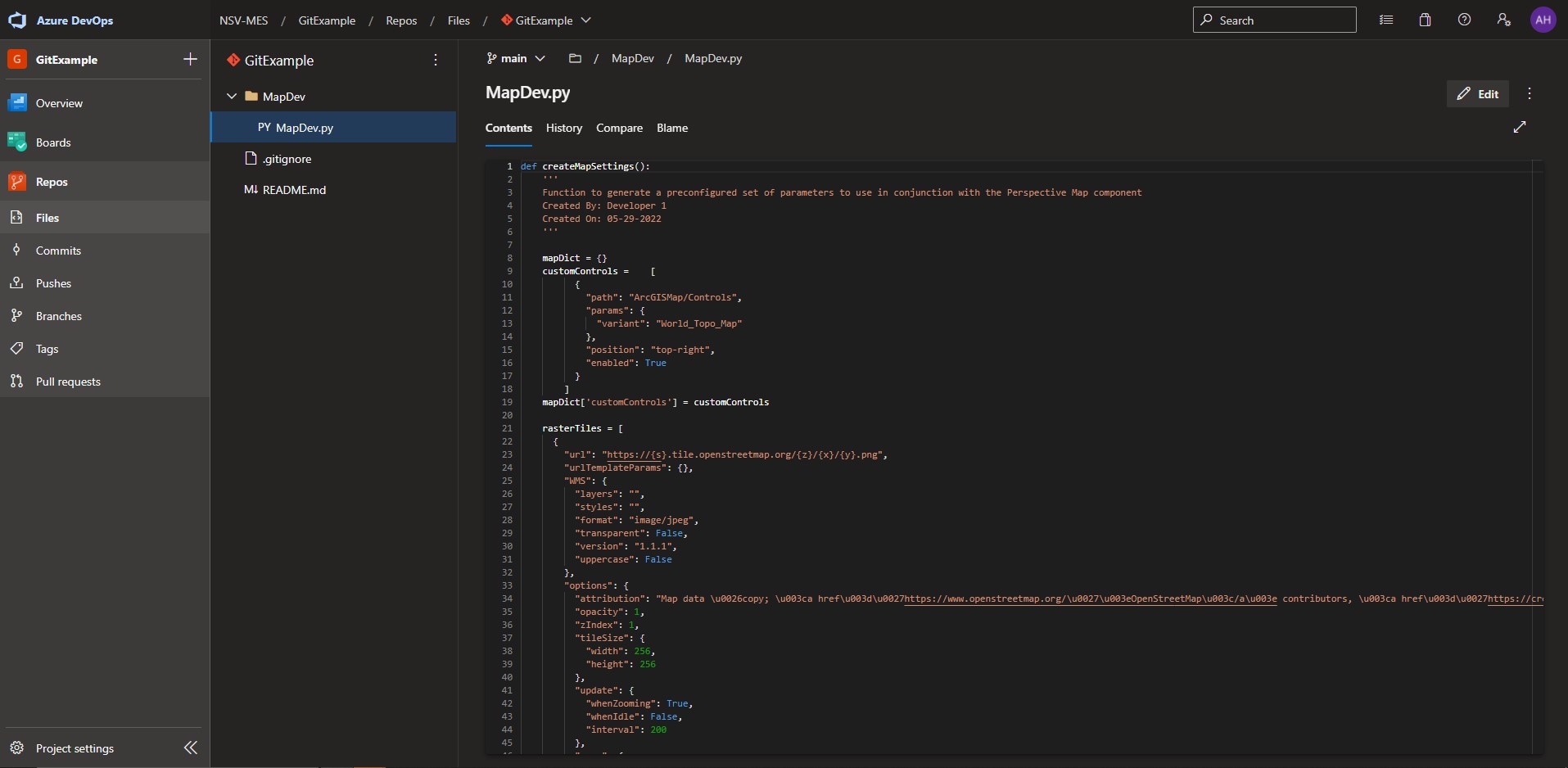
The following images show the remote repo being initialized in Azure DevOps and the file MapDev.py being loaded with only some default functions to render the standard map of Nashville as shown:
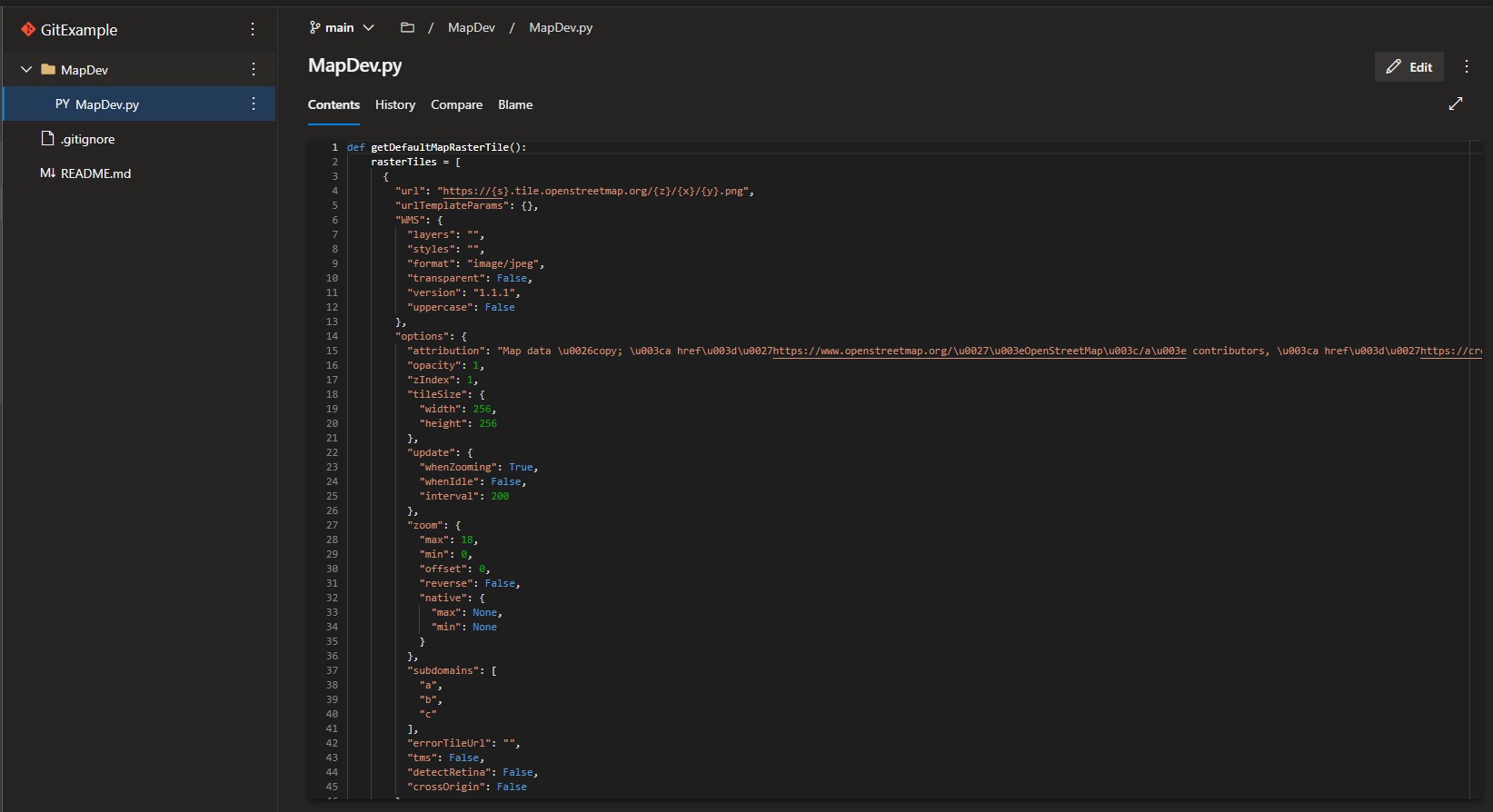
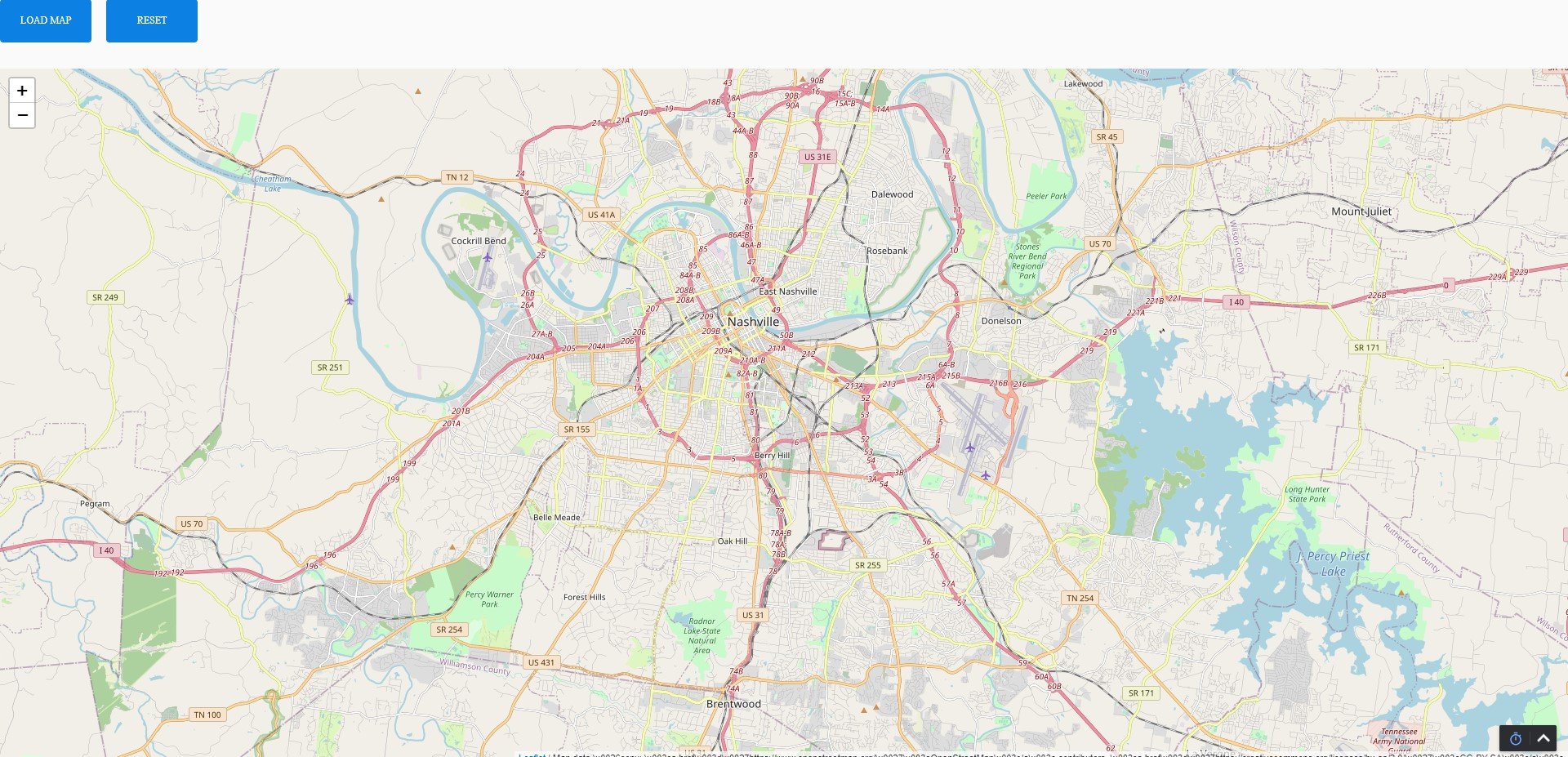
Each of the developers clones the remote repository to their local environments:
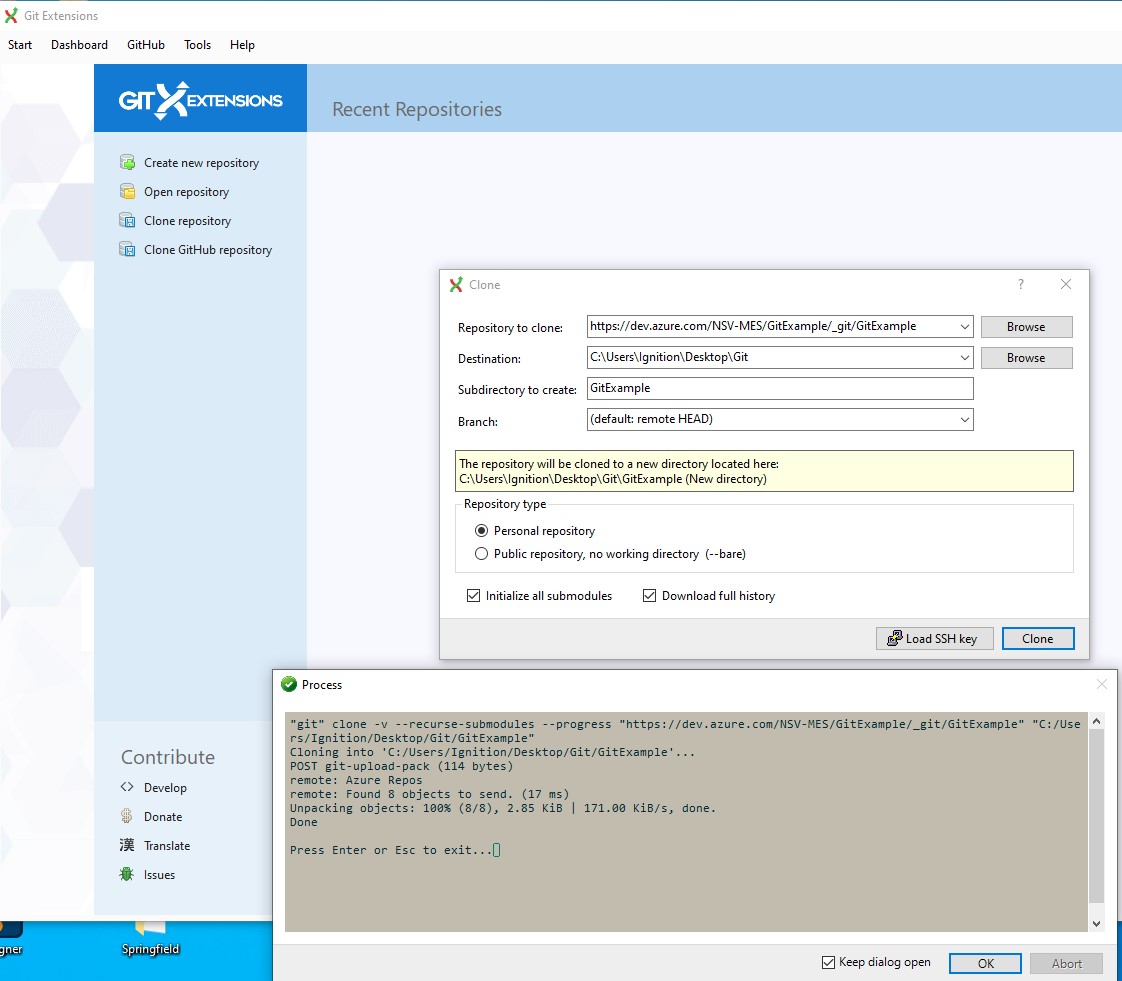
Tony first opens his Git environment. (This can be done via GUI or command line – I’m using GUI here for transparency.) And he creates a new branch off of main entitled topoMapOptions. This branch is where he intends to build the first feature.
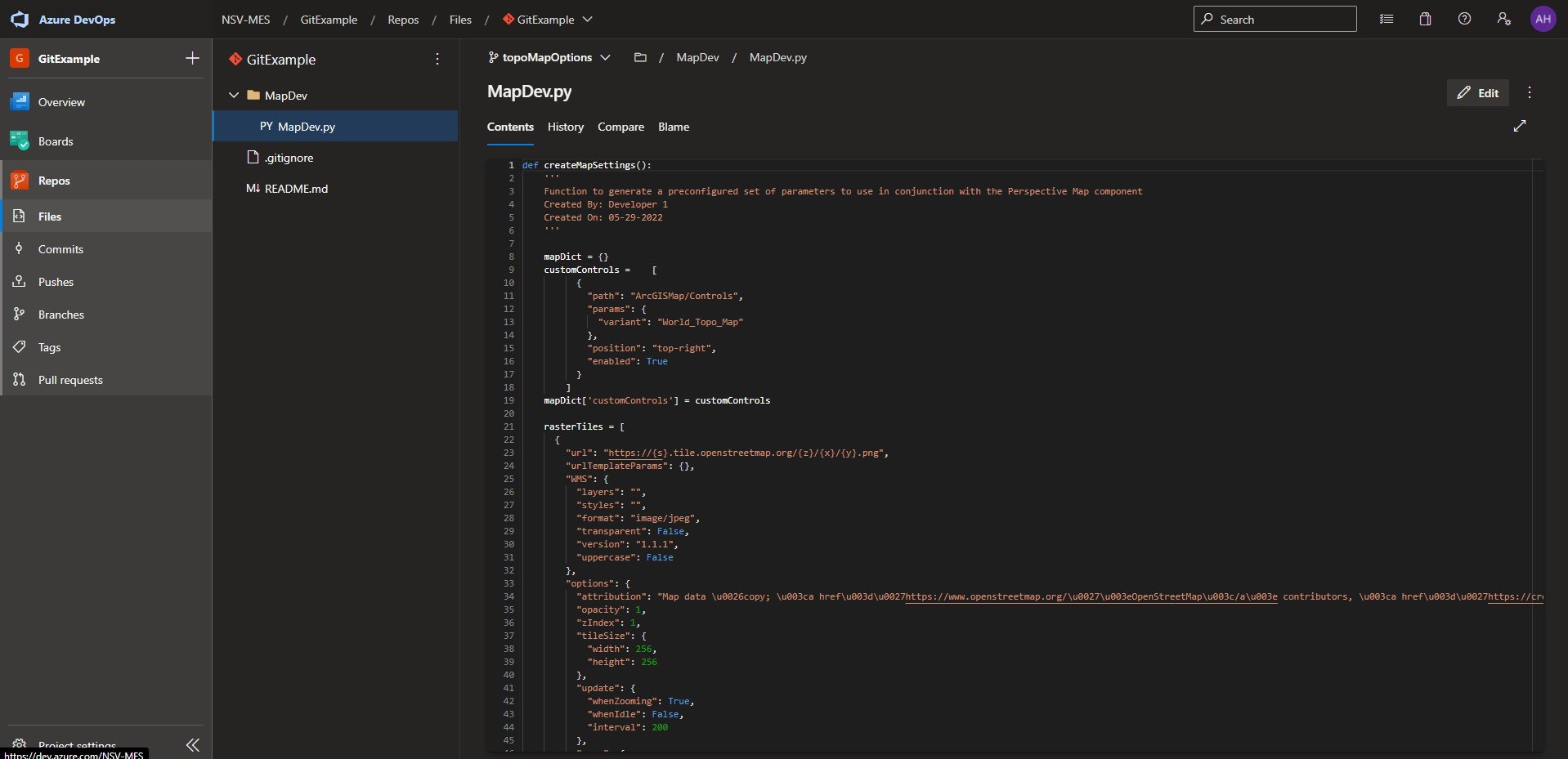
In a local environment, he then uses his Git-compatible code editor of choice to open up MapDev.py on the topoMapOptions branch and creates the function createMapSettings(). When the changes are complete, he clicks “Save” in the code editor, which saves the file in the localized directory and moves the content into the “Working Directory” of the Git repo.
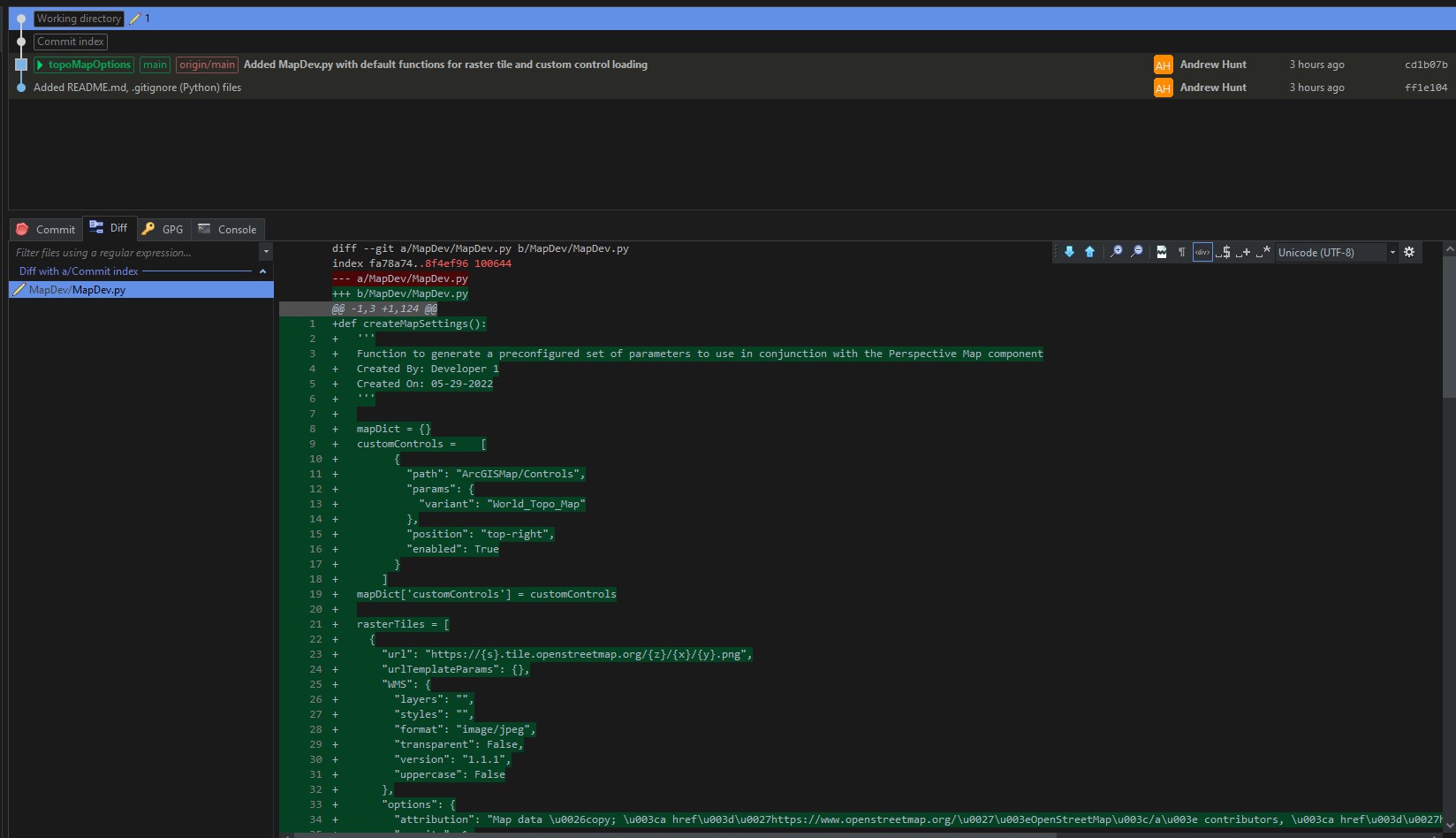
The Working Directory has not yet been cemented into the history chain as a commit, it is merely the work in progress. As such, the next step is to commit the change:
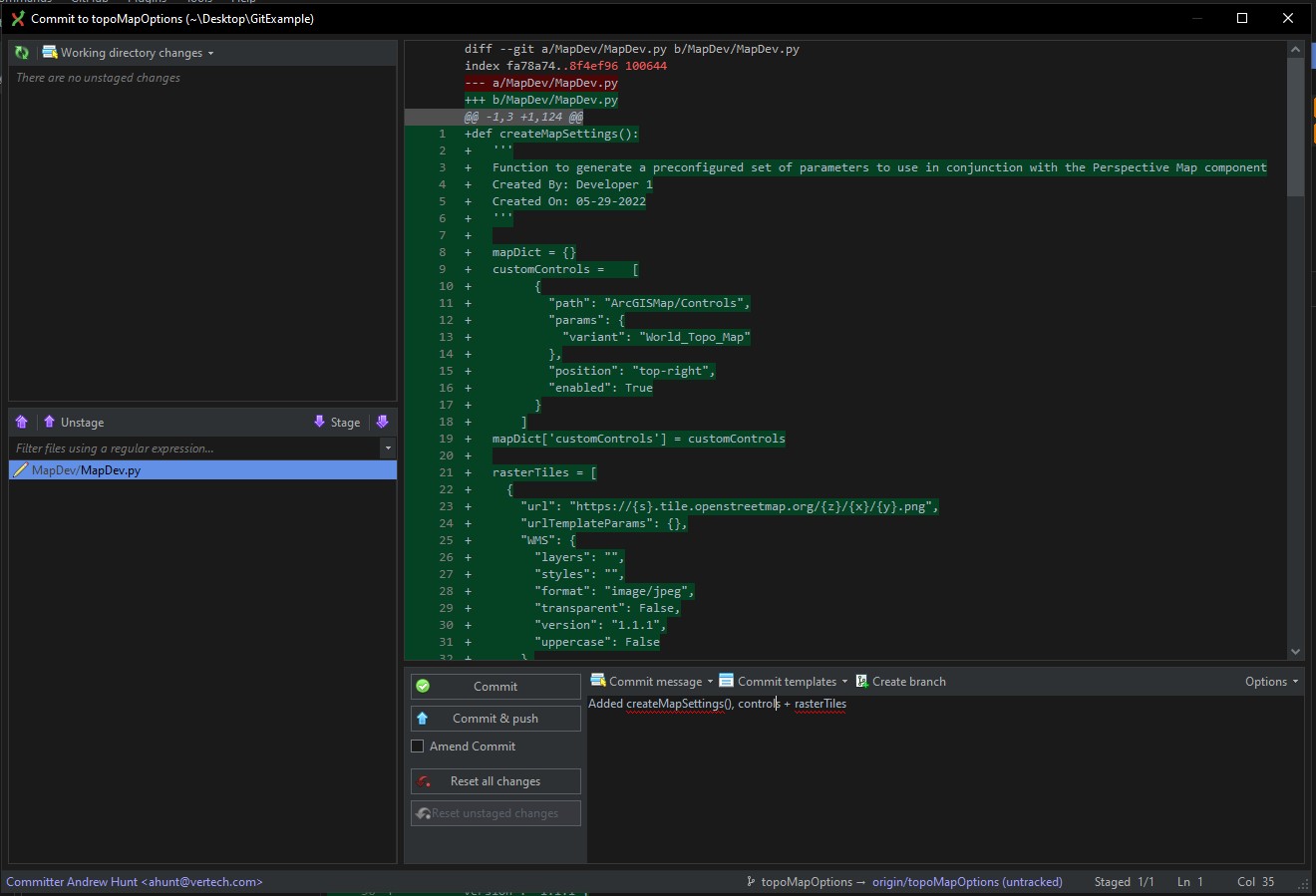
As shown above, the file was moved into the “staged” changes that will be included in the commit. Tony puts a message in the commit which will be shown in the version history and is a quick lookup of “what changed in this content”. There are now options for “Commit” or “Commit & push”.
As alluded to earlier, committing alone will create a uniquely identified copy of the codebase in the repo, but only in the local repo of Tony’s environment. Committing and pushing will not only create the commit but will also sync those changes up to the remote repo.
Tony knows this change is brand new and wants the sync immediately, so he selects the latter.
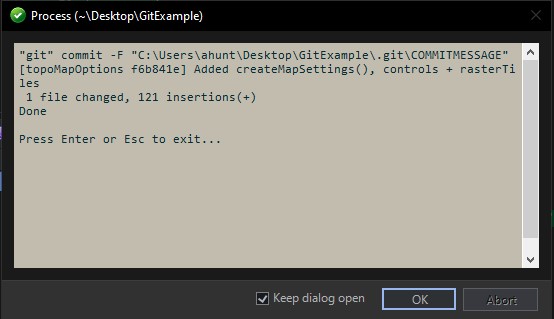
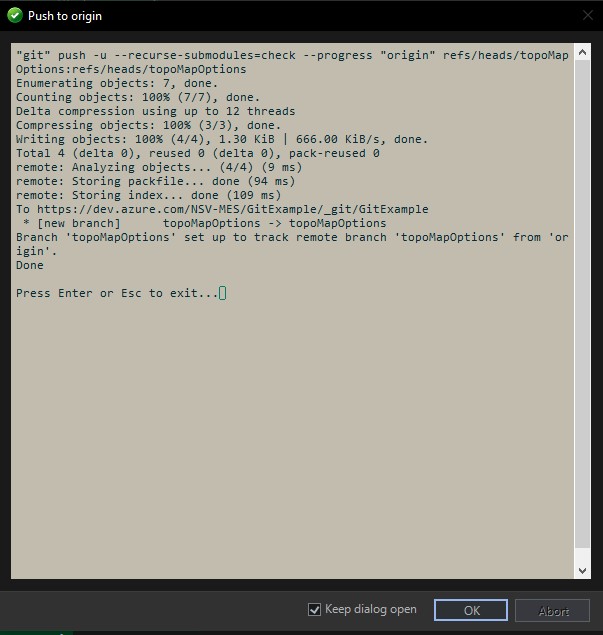
Success messages confirm that the commit and push to remote went through correctly.
On the remote repo, the main branch lacks the new changes, while the topoMapOptions contains the changes:
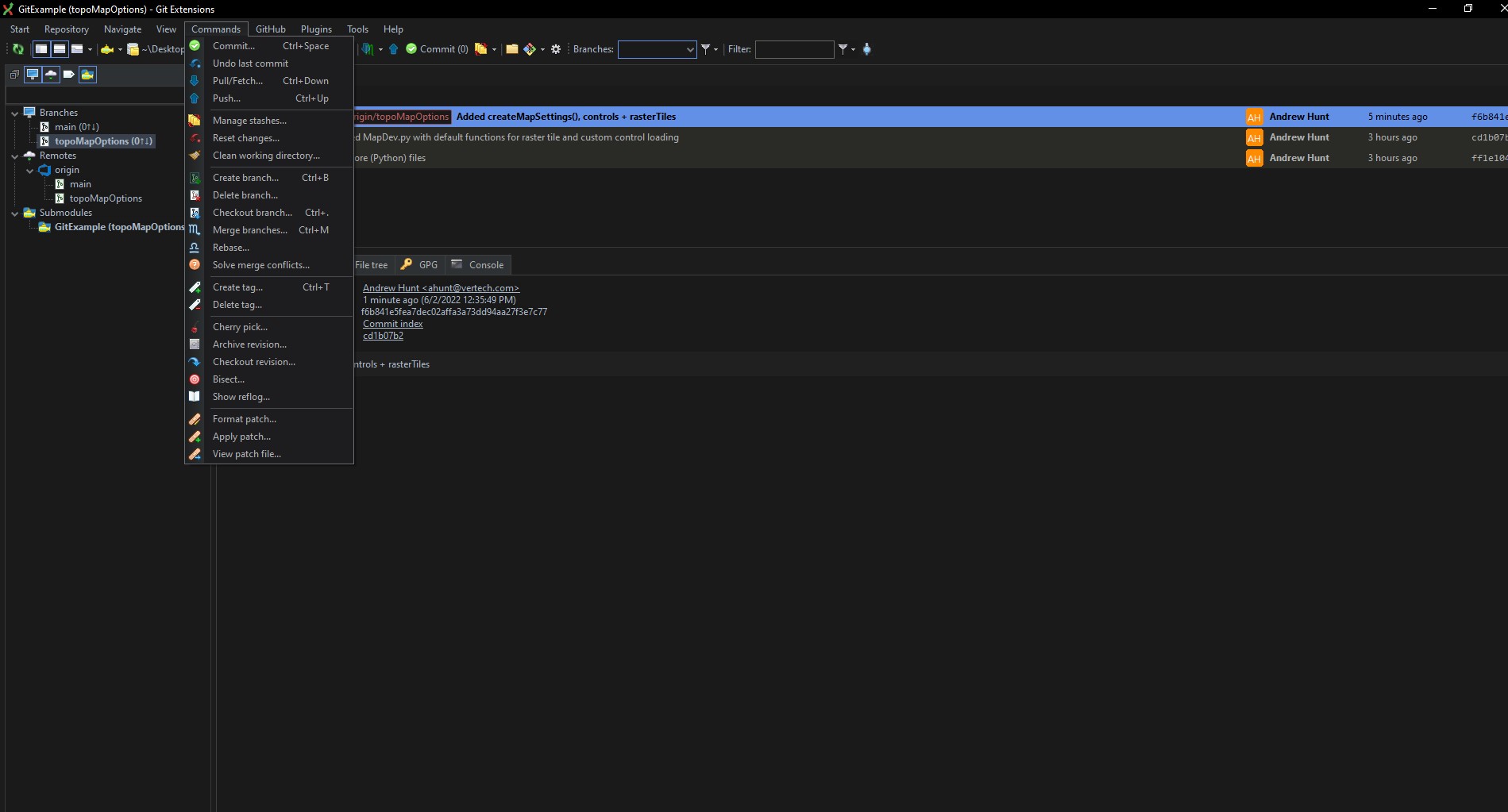
Next, Tony wants to go ahead and merge the branches and delete the development branch:
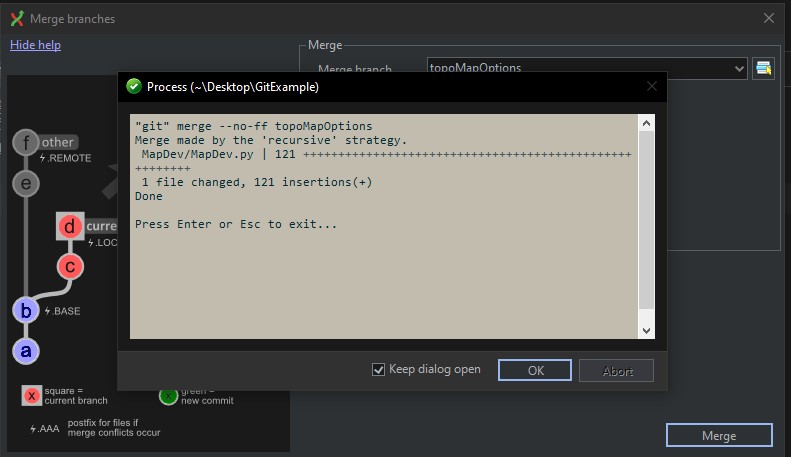
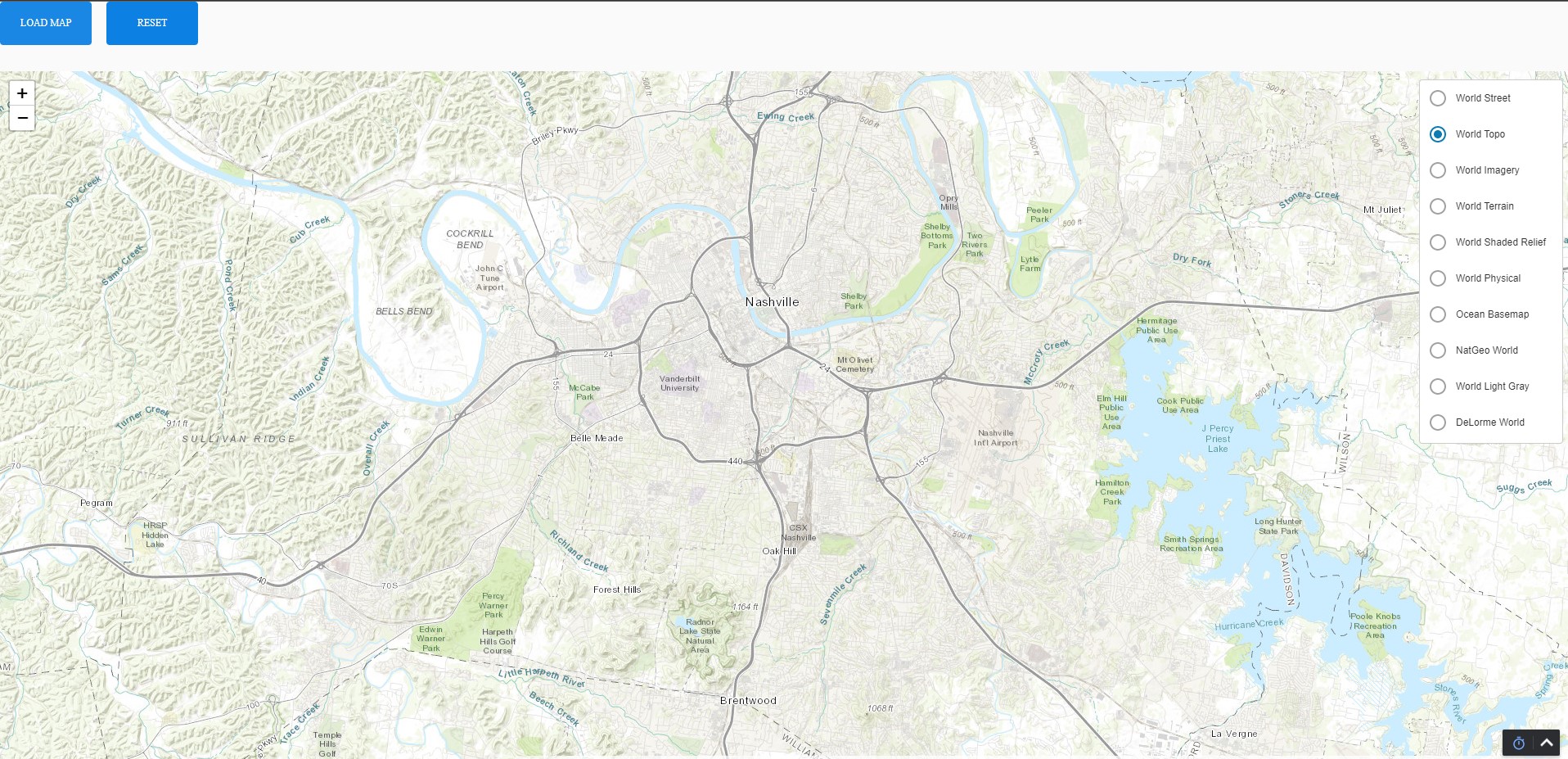
The main branch now contains the updated code, is synced between remote and local repos, and renders the following versions of the map in the runtime that have the added control menu and the ability to cycle between geographic and topological variations:
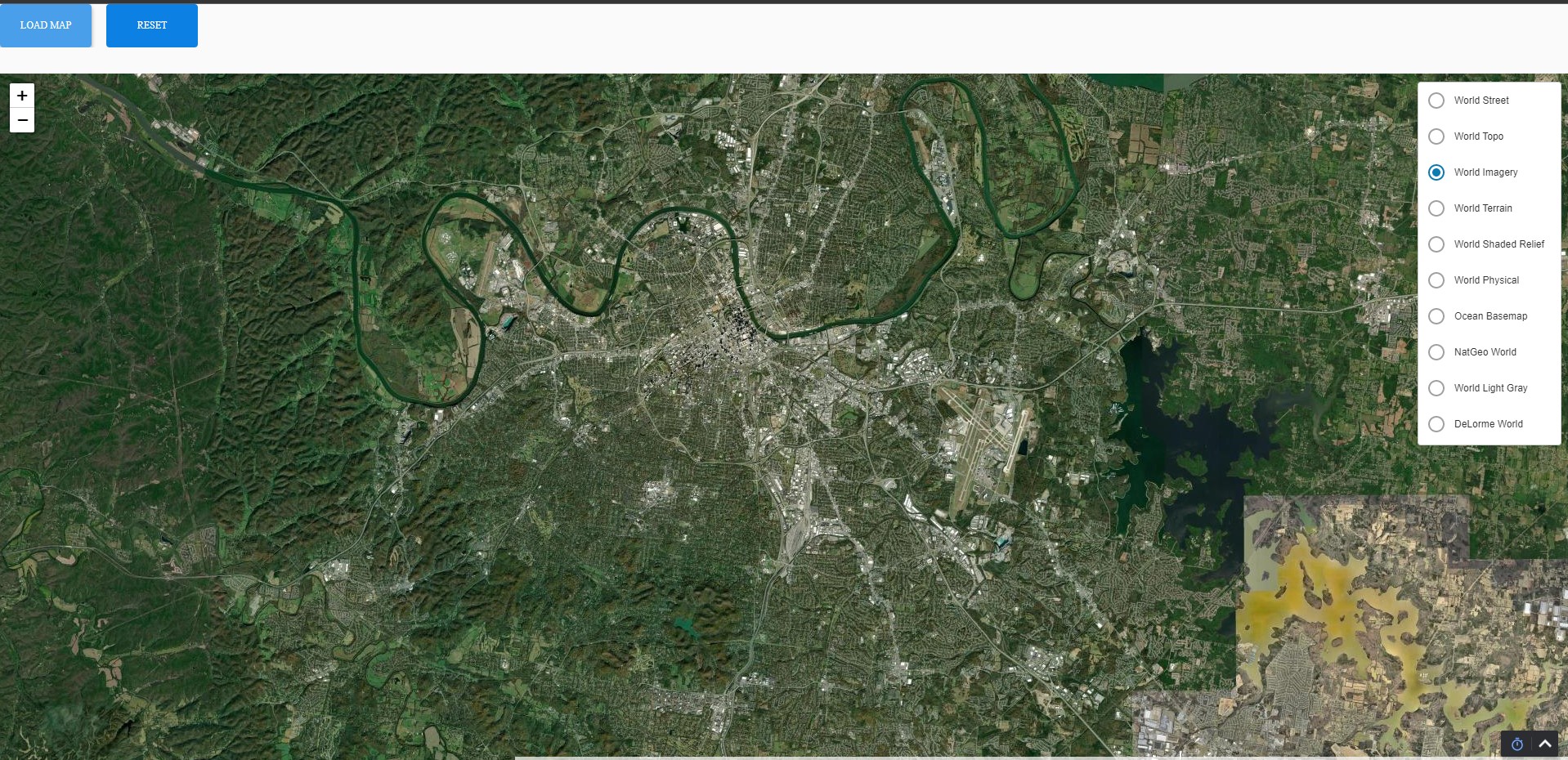
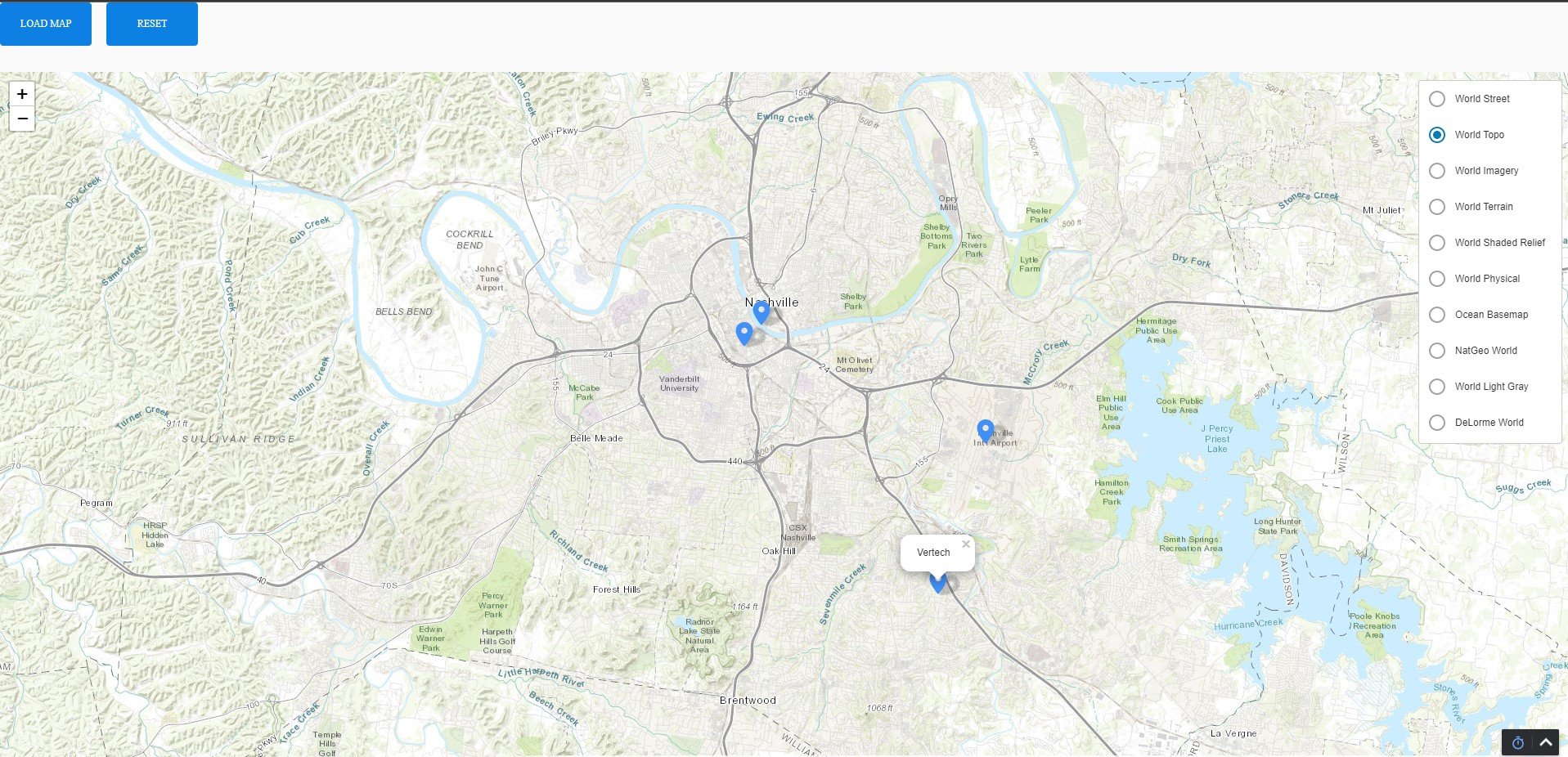
Reed’s task is to add some markers to the map showing some key Nashville locations: Bridgestone Arena, Nissan Stadium, BNA (airport), and home of the Control Freaks: Vertech Nashville.
First, he pulls the code from the remote repo down into his local repository. This means that he is now working against the copy of the MapDev.py file that Tony just finished as opposed to the initialized version from the beginning. (If he did not do this, we could get merge conflicts later on.)
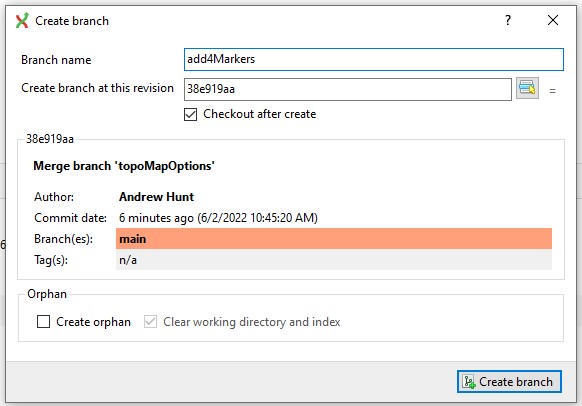
He then creates a new branch add4Markers that is spun from the main commit that was just generated by Tony’s merge:
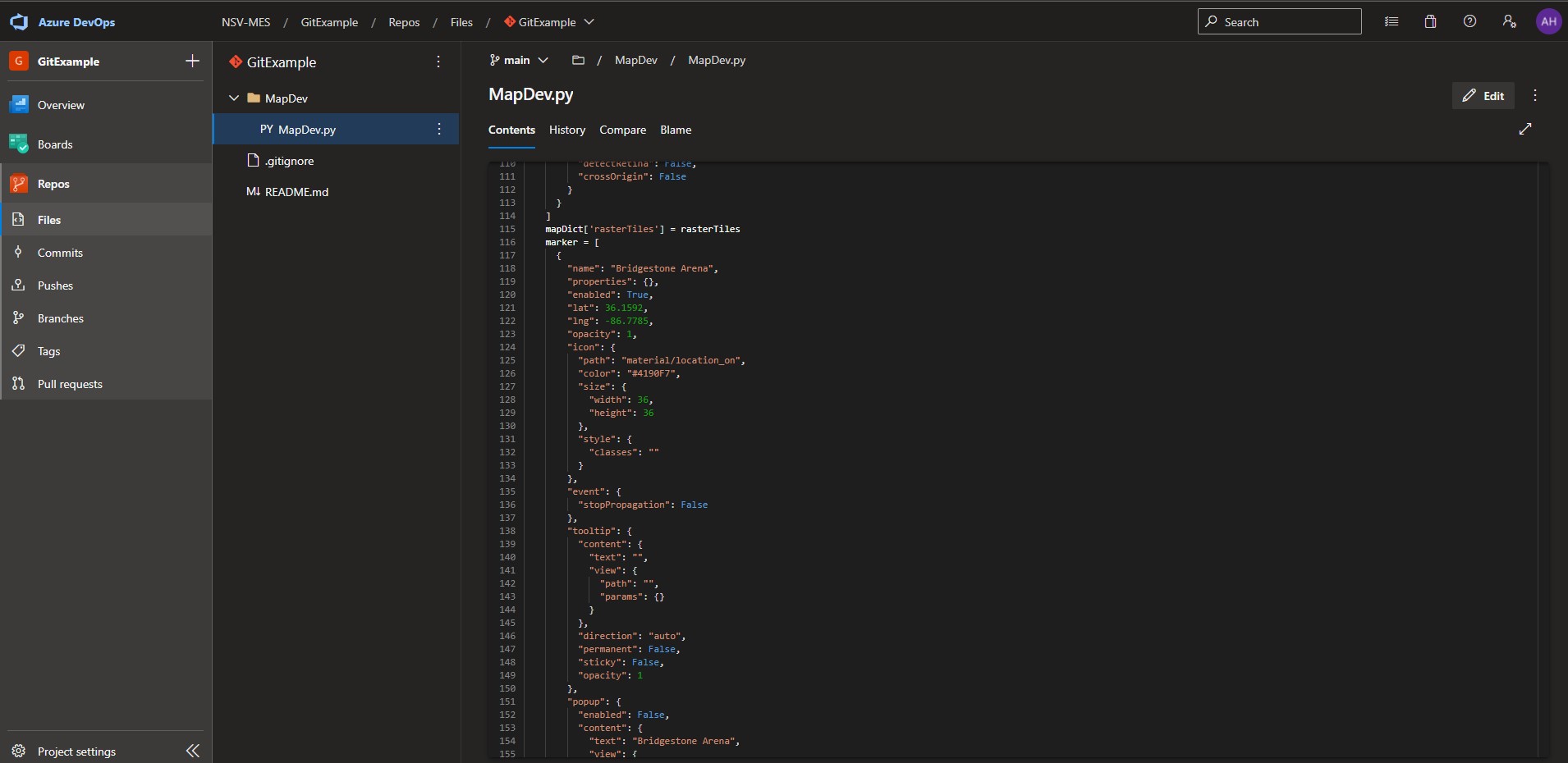
Reed opens up a code editor pointed to the new branch and edits the portion of the createMapSettings() function that writes the marker array, which was previously setting an empty array:
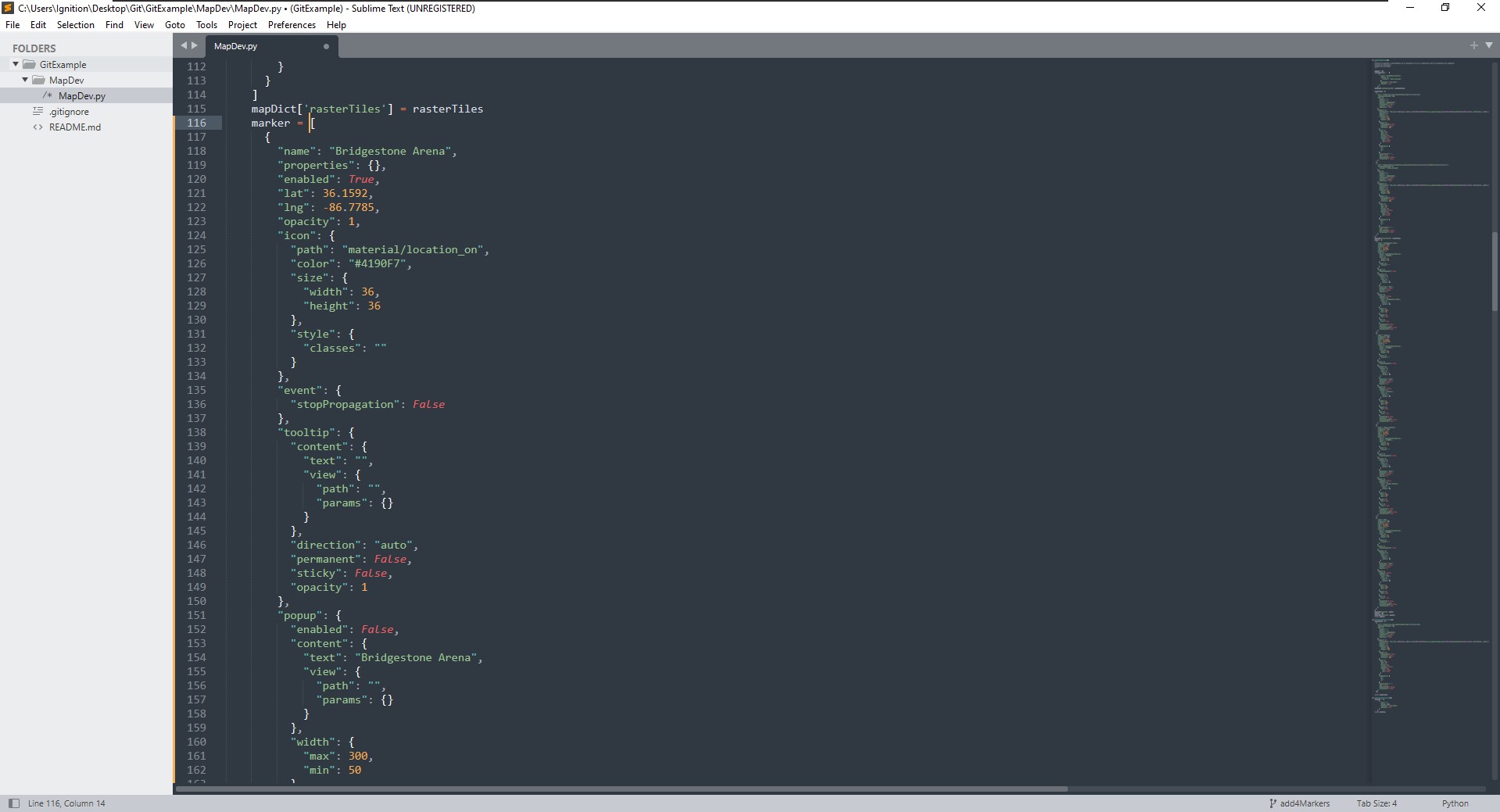
That code is moved into the working directory, committed, and pushed, like what was done before. Reed notices that the only misaligned data is the replacement of the empty array, which is intended:
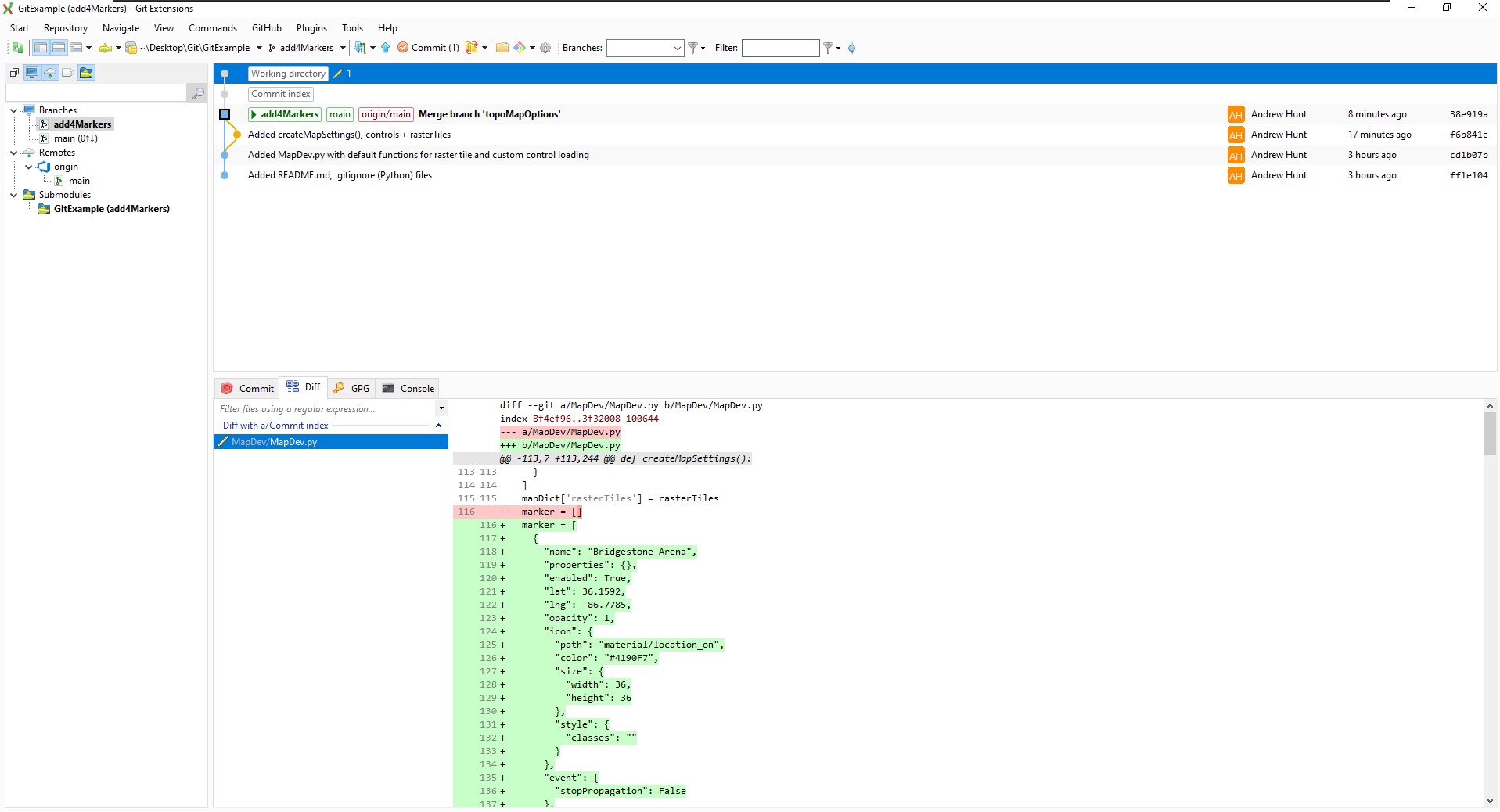
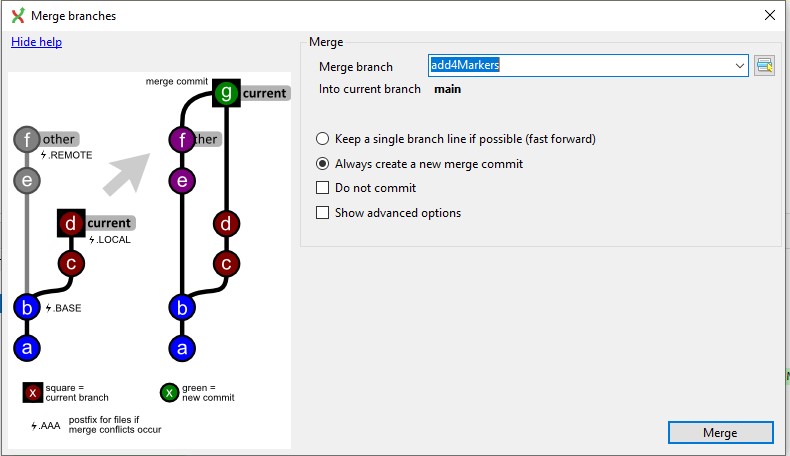
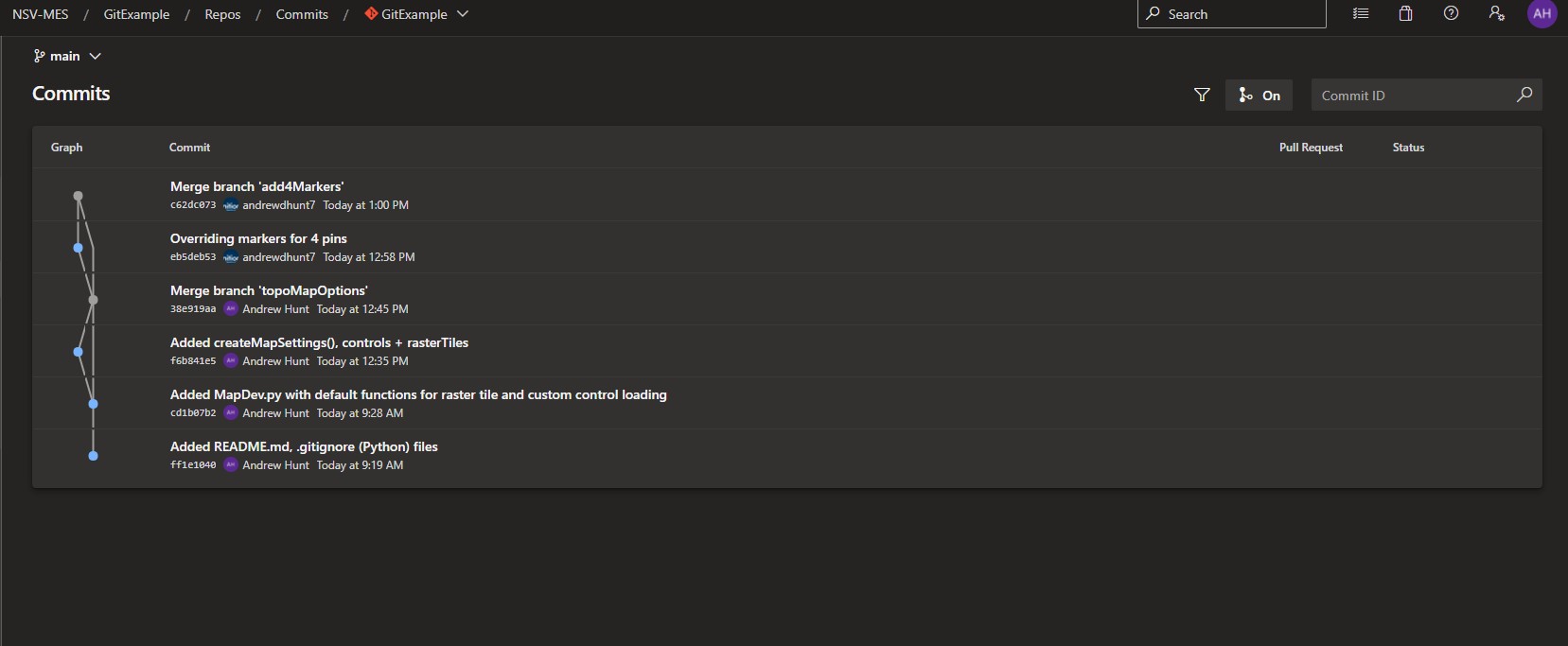
Reed then merges the branches and pushes everything up to the remote repo so that the environments are all in sync:
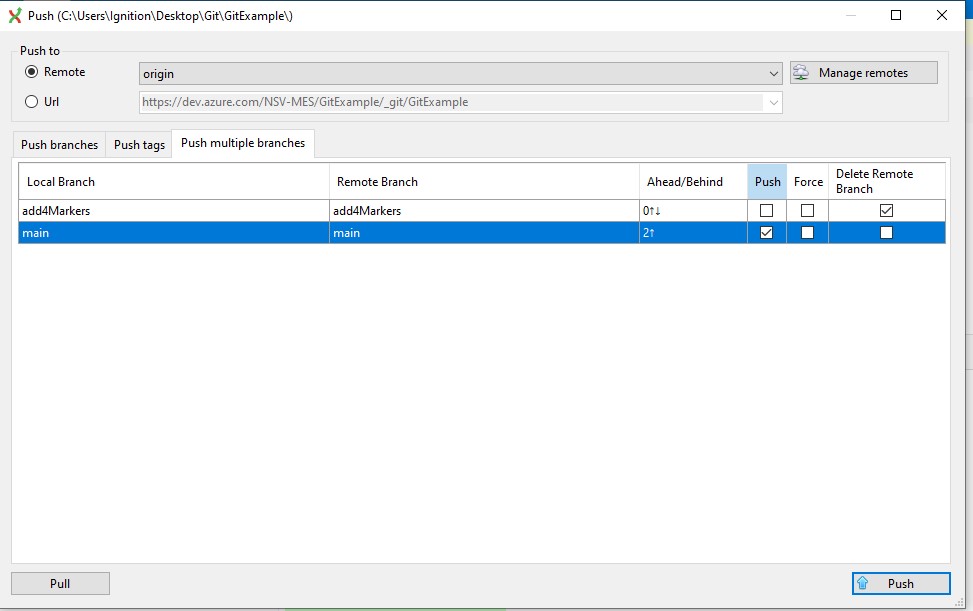
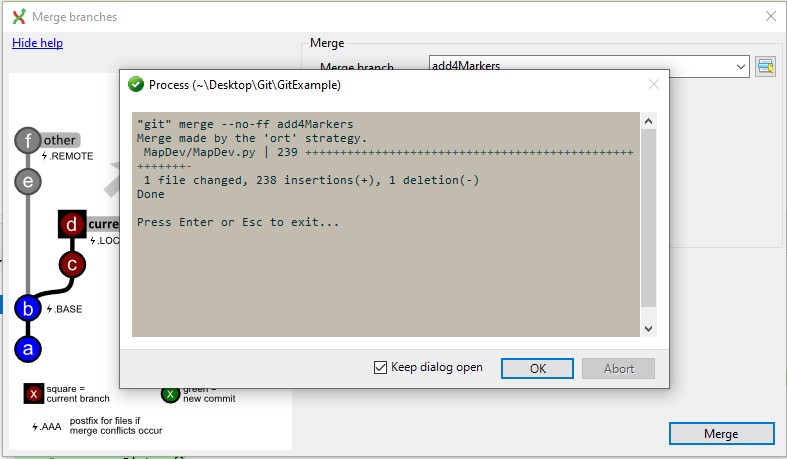
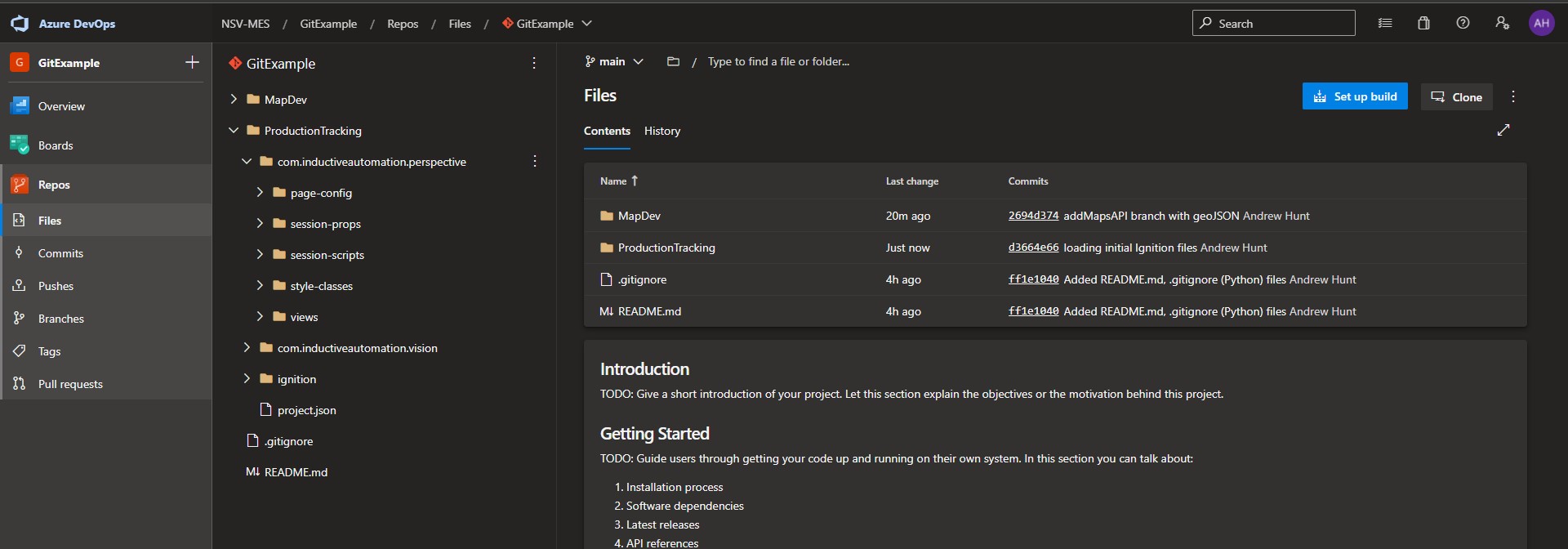
The remote now has the updated version of the MapDev.py file on a single main branch with the latest changes:
The runtime now renders with the markers and the ability to select markers to see names:
Tony is then assigned a feature to implement a call to the Google Maps API to retrieve directions from Vertech to Bridgestone Arena and render it on the map. First, he pulls the latest from the remote into his local repo:
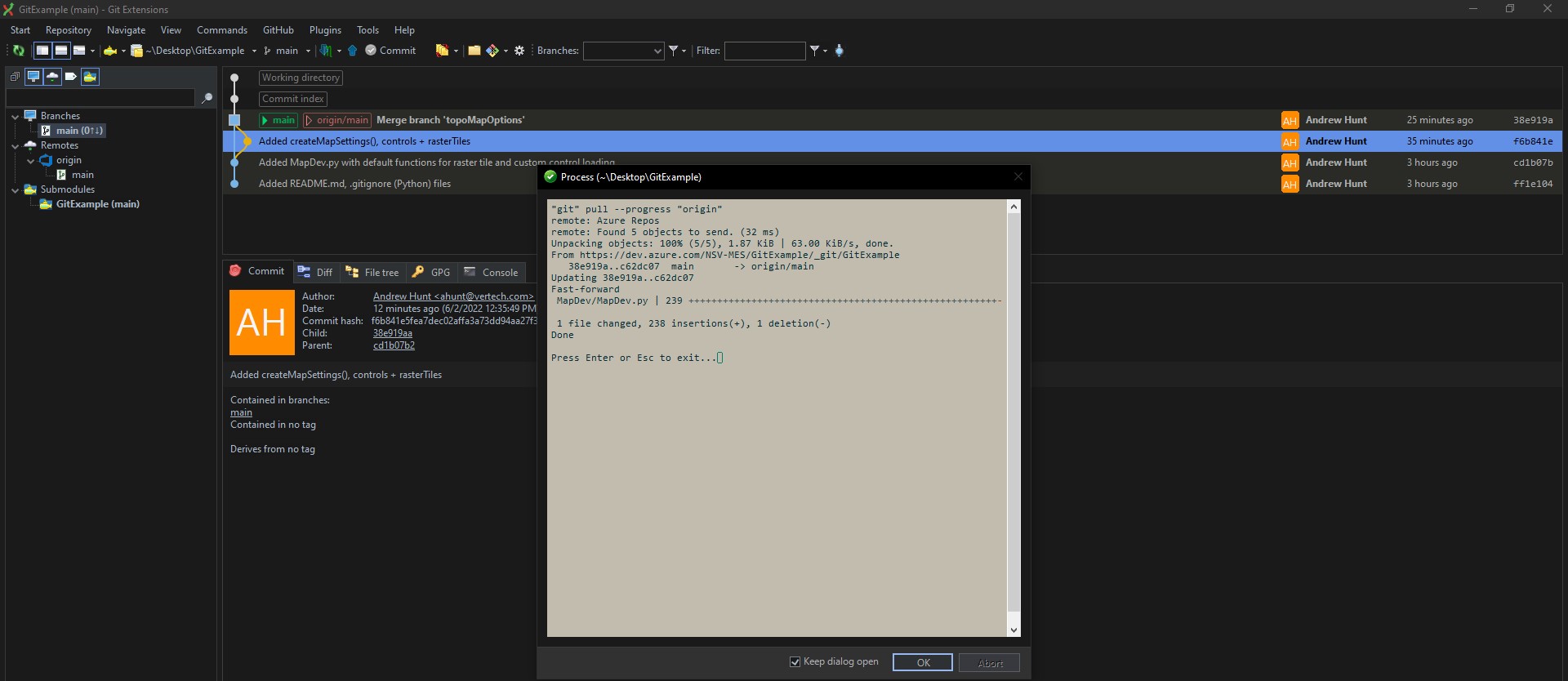
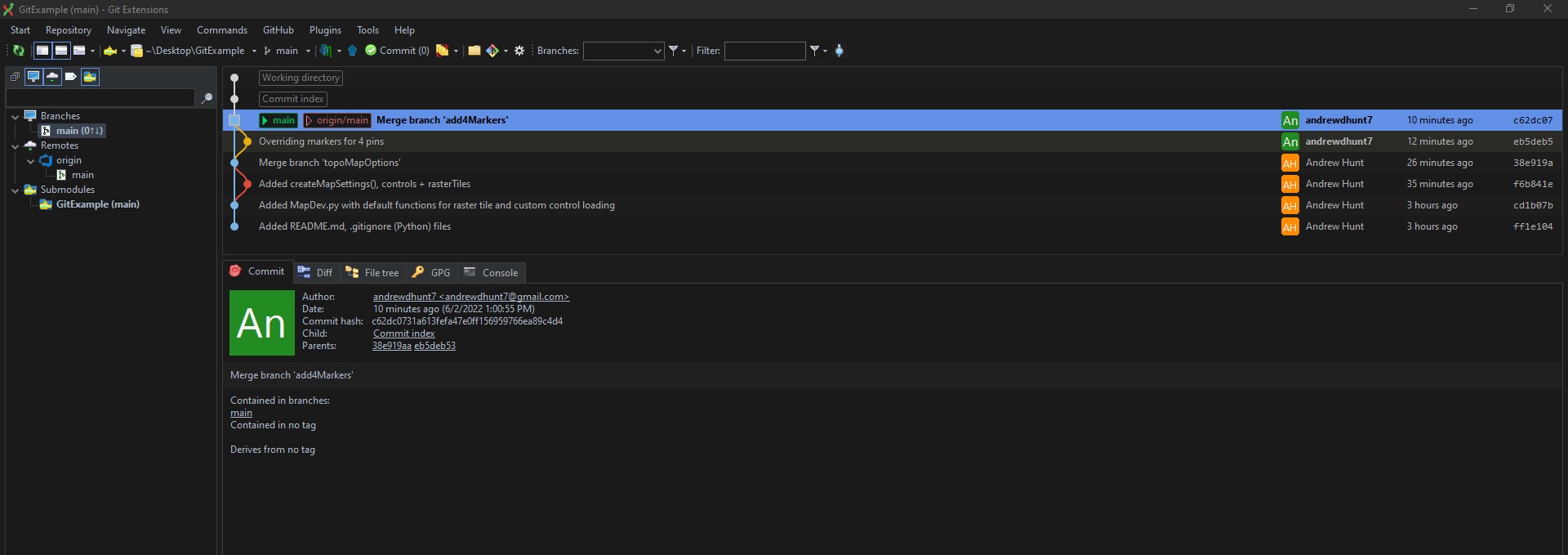
He can see the changes made by Reed. He then creates a new branch entitled addMapsAPI and makes modifications to the file on that branch. The modifications include implementing the API call to the Maps API and then running a convert function to generate the geoJSON layer as well as modifying some of the markers that Reed implemented:
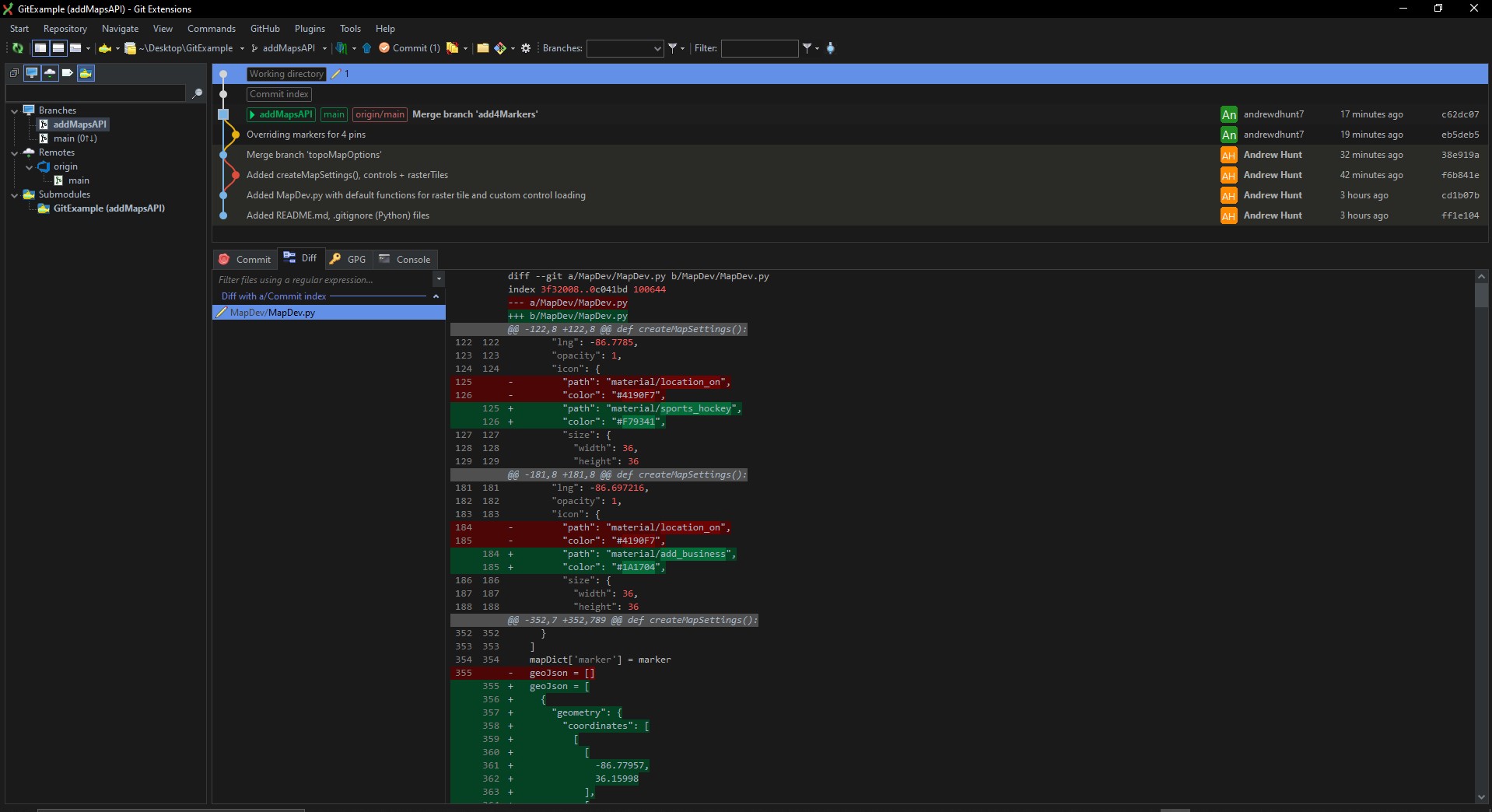
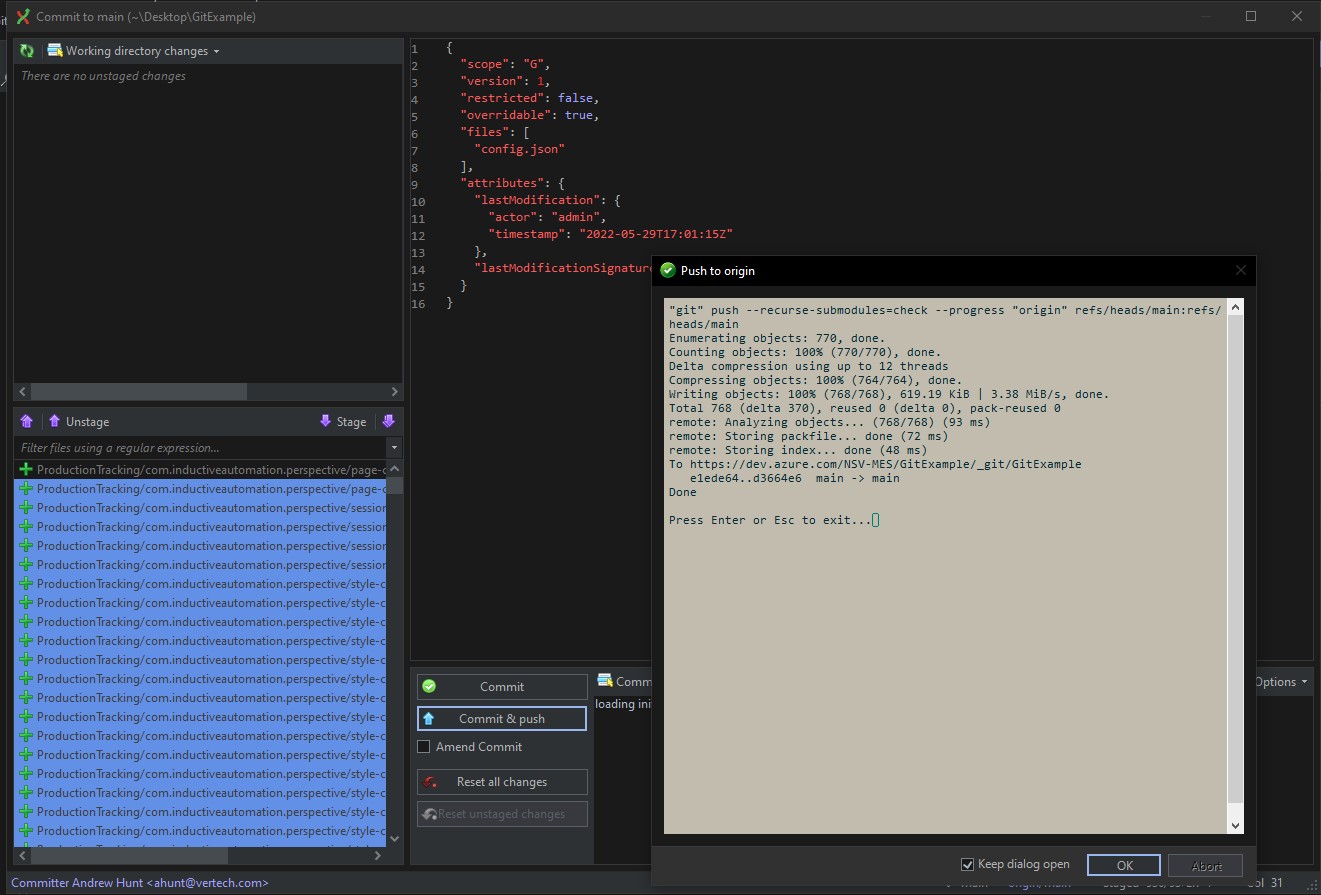
Tony commits and pushes the changes from the Working Directory into the Repos:
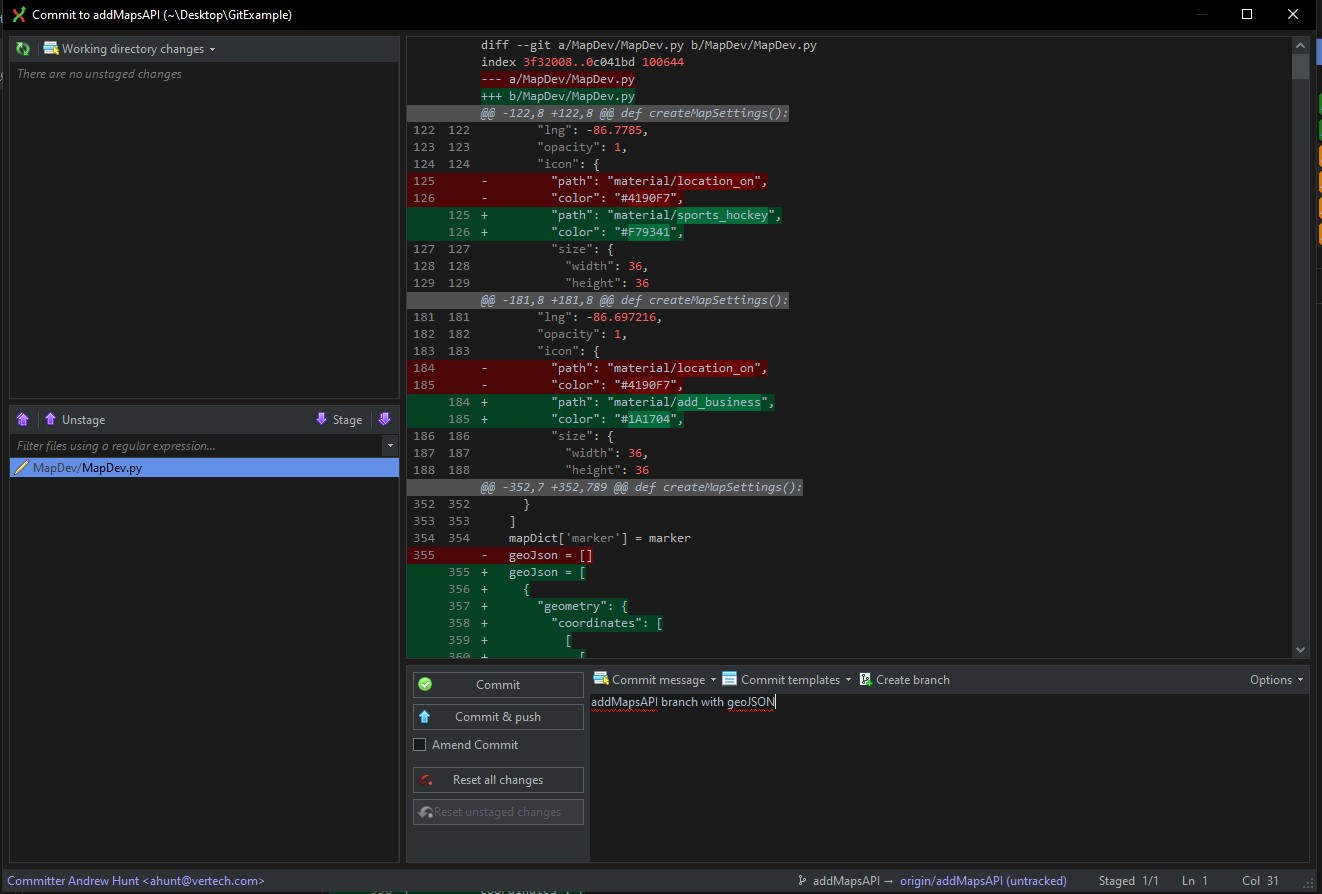
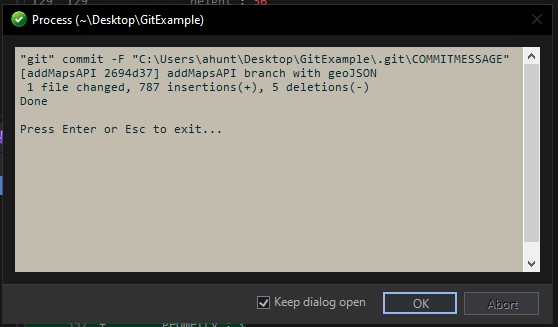
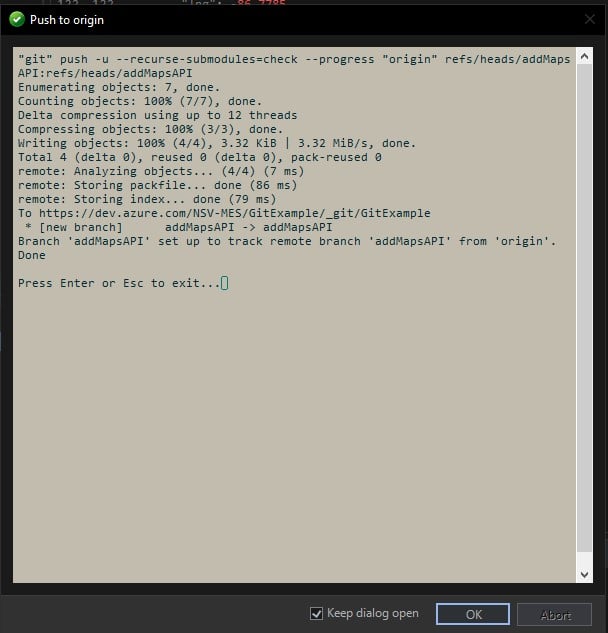
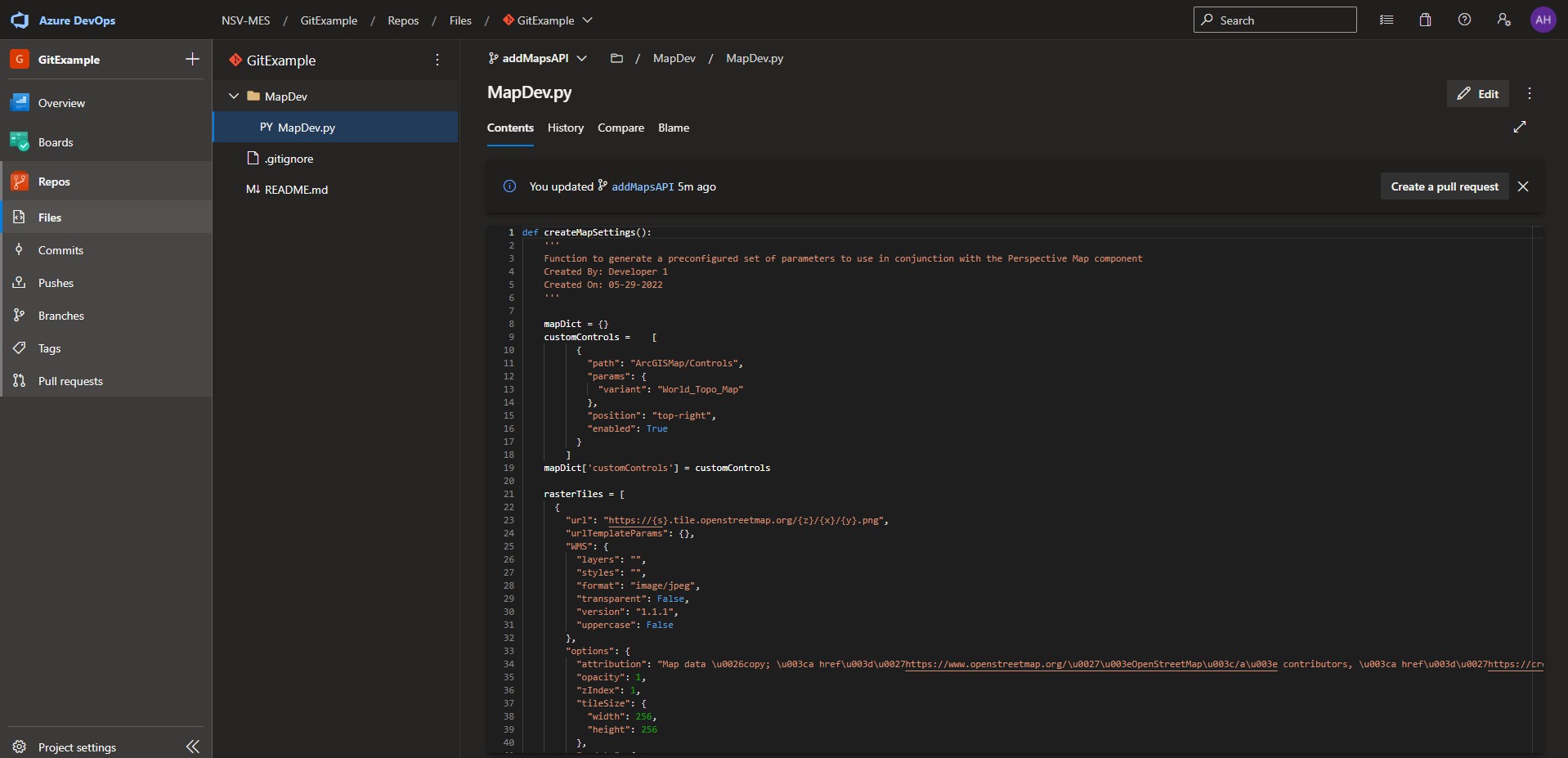
As shown above, the code is now available on the remote repo under the addMapsAPI branch. However, Tony does not know whether the marker changes he made are acceptable or not. As such, he submits a Pull Request to have the addMapsAPI branch merged into main. Now Reed and the others can review and verify that the change is acceptable.
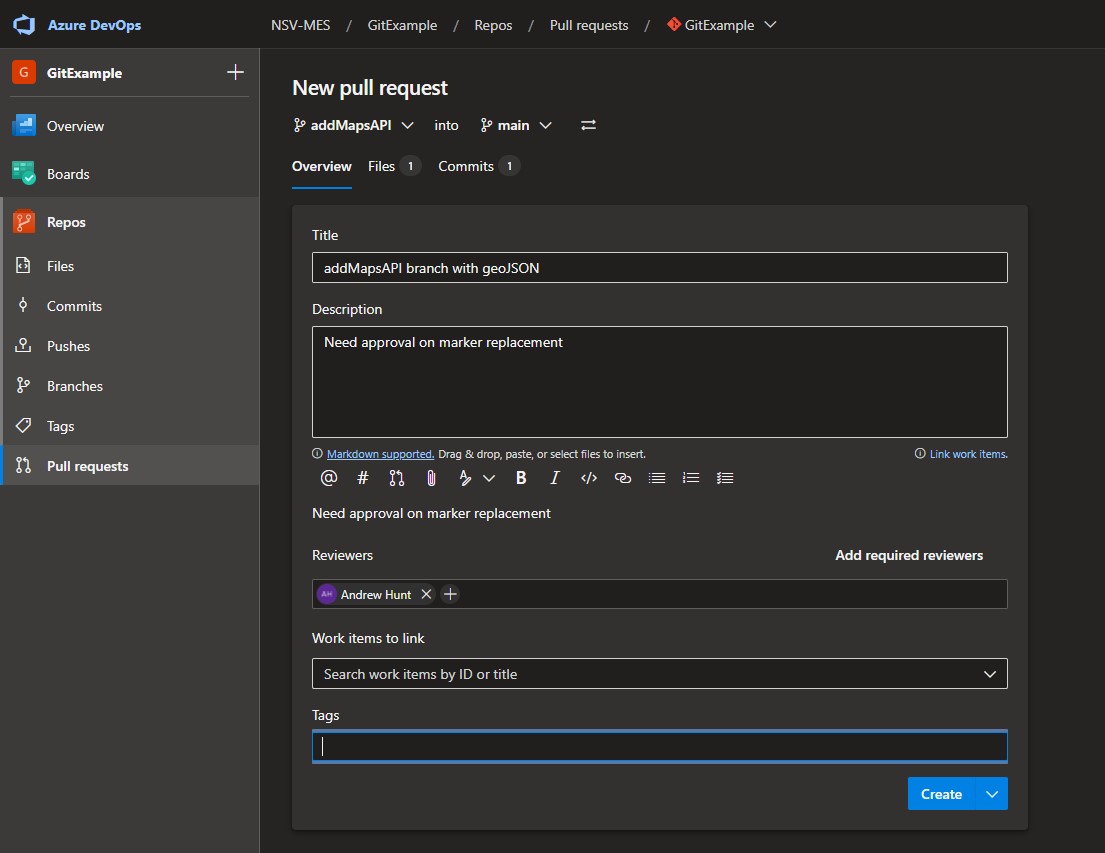
The Pull Request is then Completed:
And the code is once again realigned to only main:
Now, with all three features added, the map (only having ever been linked to main) goes from the default function starter:
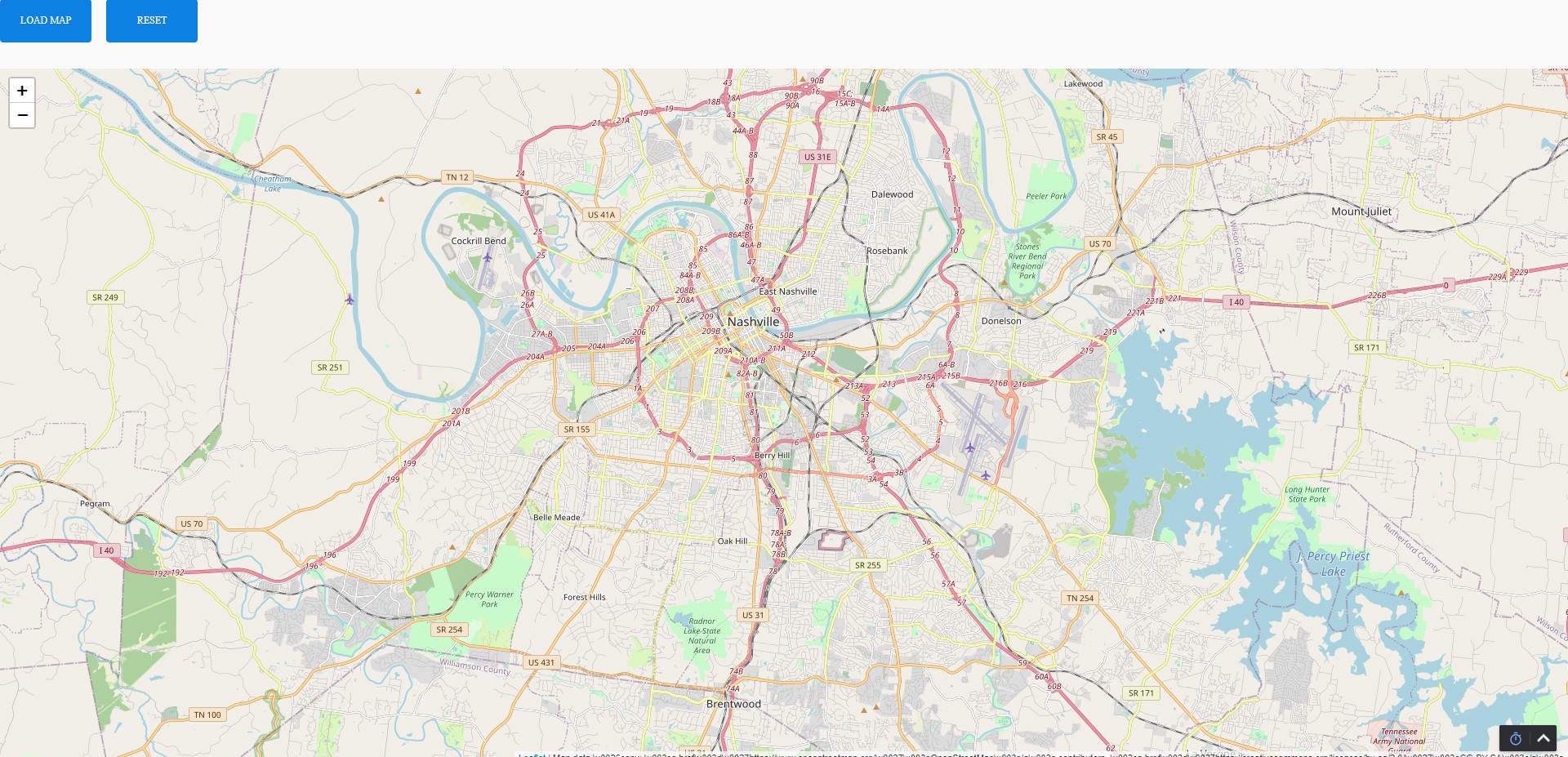
To having all 3 features implemented:
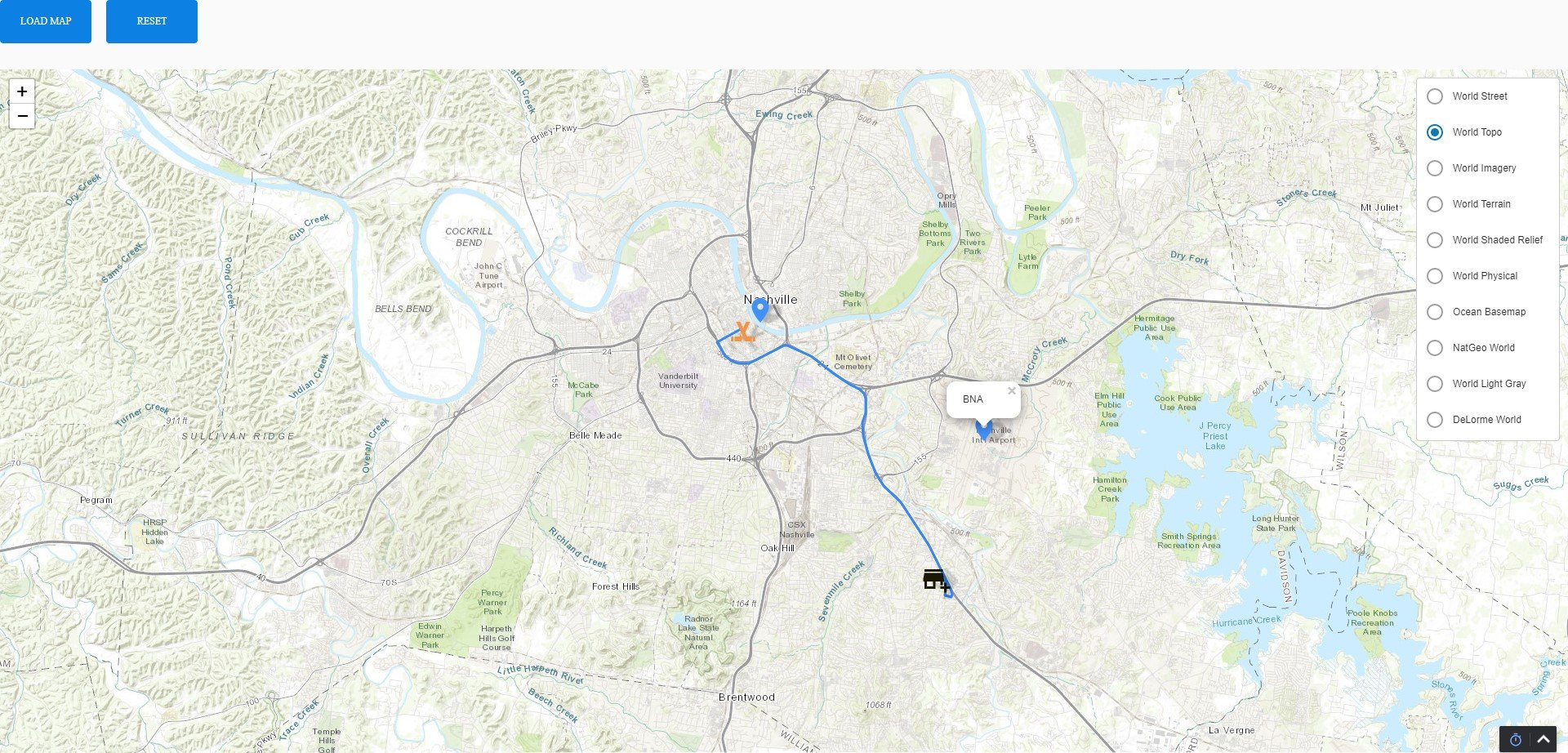
The final variation of the main branch captures the custom controls, raster tile layers, markers, and the directions geoJson generated by the API call.
As mentioned, this example was fairly streamlined and simplified, so when implementing in an organization, care needs to be taken when determining procedures for when to pull / rebase code, what the average duration or scope of a branch should be, who handles merge conflicts, and other concepts mentioned here.
The process can seem intimidating at first, but once the initial learning curve is overcome, it will seem ridiculous that these types of practices were not followed before given the number of benefits provided!
Ignition Version Release Tracking without Local Repos
Next, we will look at an example of a more simplified use case of version control using Ignition version 8.1 for an Industrial Automation solution.
There are sometimes reasons not to implement a fully integrated version control system. When the timeline is tight and there will not be room for new developers to get acquainted with the Git framework and there is not an urgent requirement for every change to be tracked, it can be better to track the incremental progress of the code in larger chunks instead.
Technology can also be a factor. For example, as of version 8.1.17 of Ignition, there are some restrictions on using version control.
Many Ignition JSON based resources are not auto-merge friendly. Resource.json files that are attached to many components in the file structure such as Perspective views have properties that are incremented every time the View is opened and not just when the configuration is modified.
There are also entities such as session properties that are difficult to track in terms of when a change is desired and when it is not. In View scripts (think message handlers, transform scripts on bindings) are compressed to a single line of GSON that makes use of new line characters in the raw string and thus is incompatible with the line-by-line Diff and merge logic shown previously.
"script": "\t\n\t## Called from Barcode Scan\n\t\n\tlogger \u003d system.util.getLogger(__name__)\n\t\n\tassemblySerialNumber \u003d payloa…
While there are some alternative workarounds to these problems, often times the most effective solution to the problem may be to simplify. At the end of the day, nothing in this document is useful whatsoever unless the way in which it is implemented for your team truly increases efficiency, transparency, collaboration, and security. In the following example, a repository with two running servers is used in such a way as to reap benefits of Git without incurring some of the overhead that can come with the Git process.
First, we initialize a remote repository with a set of Ignition gateway files (Perspective resources, Vision Windows, etc. from a project) that we want to track changes against:
Next, a series of incremental changes are made and branches are created:
The intention of the structure would be to have one server that is the “Development” server and one that is the “Staging / Test” server. At the initialization of the setup, both servers are running ProductionTracking_1.0. For the first cycle of development, the dev server builds against ProductionTracking_1.0.
All of the developers work collaboratively against that server, using Ignition’s built-in resource conflict tools, as if there was no version control in place. They do not have to worry about merging or any of the other constructs.
At the end of the first increment of work (likely the end of the first sprint, but again we will talk Scrum another day), version 1.0 of the application is released. That means that the dev server is moved onto branch ProductionTracking_1.1 and ProductionTracking_1.0 in it's final state continues to run on the Staging server. This process would repeat at each completed increment of work, with the “released” version going to staging and dev moving to the next version.
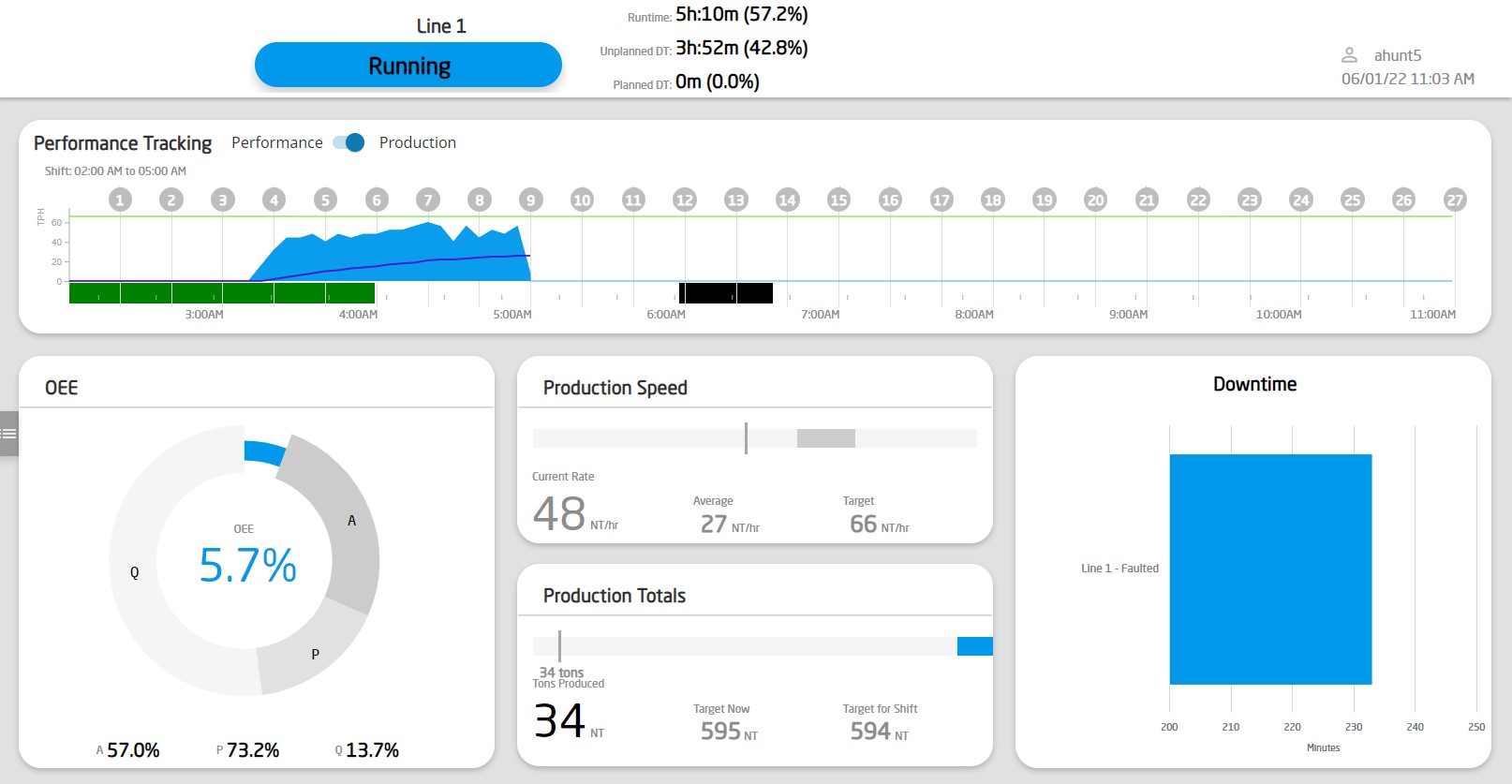
To put visuals to words, ProductionTracking_1.0 might be the Realtime data dashboards for tracking performance:
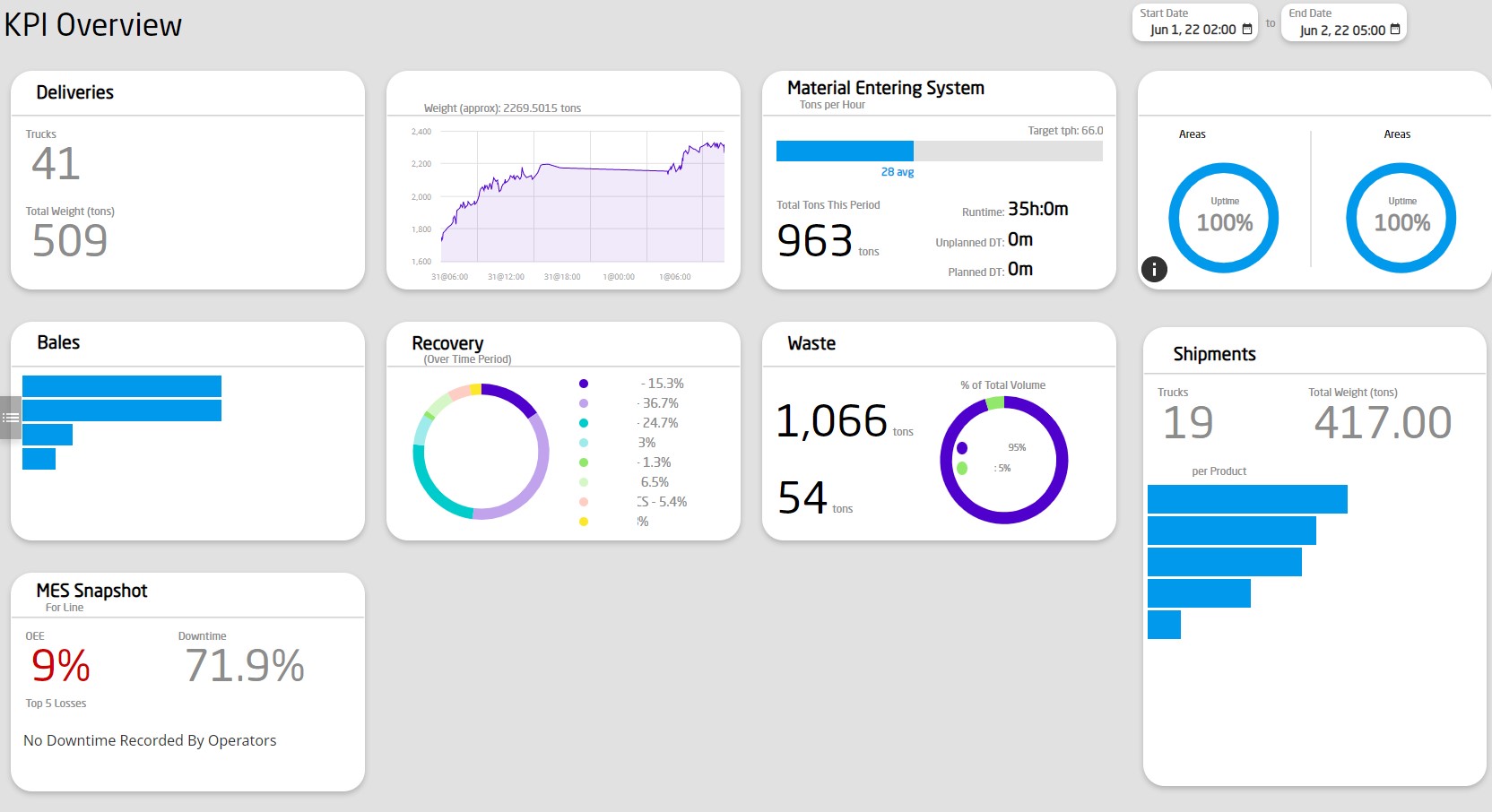
- ProductionTracking_1.1 might be the addition of a specific KPI dashboard for other personnel who need more broad data:
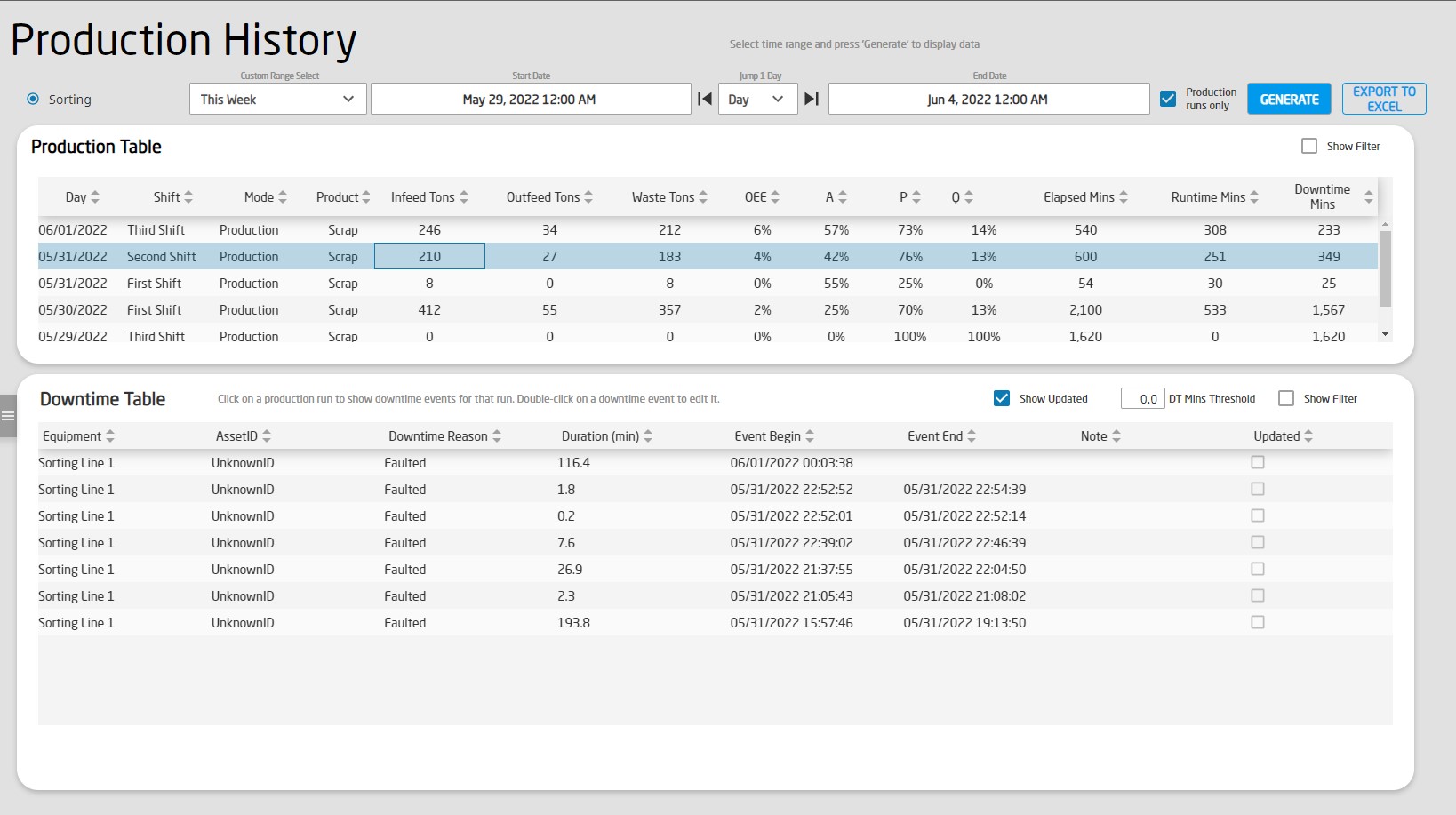
- ProductionTracking_1.2 might be the addition of a tabular history report:
- ProductionTracking_1.3 could be bugfixing and adding small features or additional screens.
The point is that at any given moment, there is a collaborative development environment and a stable staging / testing environment where it is always known what changes are present. We may not know how many times somebody clicked the “Save” button in the Ignition Designer when developing the screens within each release, but when comparing across releases, there is always full transparency.
Developers are still able to spin up isolated environments as needed should they need to do something like test significant modifications to a database schema that would disrupt existing work.
The intent of this process is twofold: First, we can maintain high visibility into the incremental progress of the system by knowing what has been deployed at each branch as well as reduce the pain of troubleshooting by easily being able to Diff resources when a regression is encountered. Second, we can isolate the live development process from the current release.
This separation allows the team to run demos, grant access to stakeholders, and perform testing without disrupting the cadence of any development work. All of these benefits are accomplished without any additional overhead to the development team. The only work involved is setting up the creation / moving of branches and loading code onto the servers (nearly all of which can be automated with tools such as Azure DevOps Pipelines).
Well, that wraps up our series on Git! We hope you enjoyed these use cases. Go back and read Git Part 1: Git Started if you haven't already. And, as always, please reach out if you have any questions or leave a comment below.





Comments